In computational physics and astrophysics, many problems reduce to two fundamental kinds:
Root finding: Where does a function vanish? I.e., solve .
Optimization: Where does a function reach an extremum (minimum or maximum)? I.e., solve .
These two kind of problems are deeply connected. Optimization often boils down to root finding on the derivative. And root finding sometimes requires optimization-like strategies to accelerate convergence.
Some classic examples of root finding include:
Solving Kepler’s equation to predict planetary orbits.
Finding eigenfrequencies of stellar oscillations by locating roots of characteristic equations.
as well as optimization:
Determining the launch angle of a projectile for maximum range.
Fitting astrophysical models to observational data by minimizing a chi-square error function.
Training machine learning models for data analysis in astronomy.
In simple cases, closed-form solutions exist (e.g. projectile motion without air drag). However, in realistic systems, equations are often nonlinear, high-dimensional, and analytically unsolvable. Numerical root finding and optimization methods are the only way to solve these systems.
General Framework of Interating Algorithms¶
Root finding means solving
Many algorithms approach this through iteration: starting from an initial guess, we repeatedly update until the error is small.
Fixed-Point Viewpoint¶
A powerful way to unify root-finding methods is to rewrite the problem as a fixed-point equation:
Then we can iterate:
The solution is a fixed point of . If the update rule is well chosen, the iteration converges to .
Convergence Criterion¶
Near the fixed point , expand in a Taylor series:
Therefore,
It is clear that,
If , the error shrinks, and the iteration converges.
If , the iteration diverges.
The closer is to 0, the faster the convergence.
This provides a general way to compare methods.
Classical Root Finders¶
As we will soon see, classical root finding methods can be fitted into this picture.
Bisection Method: Is repeatedly shrinking an interval where the root must lie. The update rule is kind of a “double fixed-point scheme” where both the upper and lower bounds converge to the root. It is guaranteed to converge but only linearly.
Newton–Raphson Method: Corresponds to choosing
If , this converges quadratically near the root.
Secant Method: Uses the same Newton update rule, but replaces with a finite difference. This still fits into the fixed-point framework, with a convergence rate between bisection and Newton.
Thus, all root-finding methods can be viewed as different choices of , with a trade-off between robustness and speed.
def g(x):
return (x + 2/x)/2
x = 1.0
for i in range(5):
print(f"Iteration {i}: x = {x}")
x = g(x)Iteration 0: x = 1.0
Iteration 1: x = 1.5
Iteration 2: x = 1.4166666666666665
Iteration 3: x = 1.4142156862745097
Iteration 4: x = 1.4142135623746899
which converges very quickly to .
Root Finding Methods¶
Bisection Method¶
The Bisection Method is the simplest root-finding algorithm. It trades speed for guaranteed convergence. This makes it the “workhorse” method when robustness is more important than efficiency.
Suppose is continuous on an interval . If and have opposite signs, then by the Intermediate Value Theorem, there exists at least one root in .
The bisection method works by repeatedly halving the interval:
Compute the midpoint .
Evaluate .
Select the half-interval or that contains the sign change.
Repeat until the interval is smaller than a desired tolerance.
Each step reduces the interval length by half:
After iterations, the uncertainty in the root is
Although this convergence “exponentially” in terms of number of steps , we do not call this expoential convergence. Instead, “convergence” in numerical analysis is usually from a step size, i.e., for bisection method. As scales only linear to , bisection method is only linear convergence. It is reliable, but slower than other methods that we will introduce later.
def bisection(f, a, b, tol=1e-6, imax=100):
if f(a)*f(b) >= 0:
raise ValueError("f(a) and f(b) must have opposite signs.")
for _ in range(imax):
m = 0.5*(a+b)
if f(m) == 0 or (b-a)/2 < tol:
return m
if f(a)*f(m) > 0:
a = m
else:
b = m
raise ValueError("Maximum iterations reached without convergence")Let’s solve , which has a root between 1 and 2.
def f(x):
return x**3 - x - 2
root = bisection(f, 1, 2, tol=1e-6)
print("Approximate root:", root)
print("f(root) =", f(root))Approximate root: 1.5213804244995117
f(root) = 4.265829404825894e-06
import numpy as np
import matplotlib.pyplot as plt
X = np.linspace(1, 2, 101)
Y = f(X)
plt.plot(X, Y, label="f(x)")
plt.plot(root, f(root), "o", label="Root")
plt.axhline(0, color="black", lw=1)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend()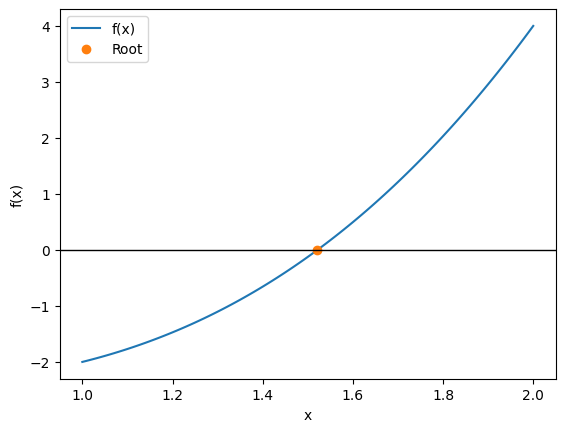
The bisection method is the most robust way to refine a root by repeatedly shrinking the search interval. Because it is so basic, it is one of the algorithm explicitly required by ASTR 513!
Newton-Raphson Method¶
The Newton-Raphson Method is one of the most important and widely used root-finding algorithms.
Unlike bisection, which only uses function values, Newton’s method leverages the derivative to achieve much faster convergence, but at a cost of robustness.
Suppose we want to solve . Expand around a current guess with a first-order Taylor expansion:
The root of this linear approximation occurs at:
This is the Newton update rule. It can also be seen as: “Draw the tangent line at ; where it crosses the x-axis becomes .”
Quadratic convergence: If the initial guess is close to the true root , the error shrinks roughly like
meaning the number of correct digits roughly doubles at each step.
Fragility:
If , the method fails (division by zero).
If the initial guess is far from the root, the iteration may diverge or converge to the wrong root.
Thus, Newton’s method is fast but fragile.
def newton(f, fp, x0, tol=1e-6, imax=100, history=False):
X = [x0]
for _ in range(imax):
fn, fpn = f(X[-1]), fp(X[-1])
if fpn == 0:
raise ValueError("Derivative is zero: Newton step undefined.")
X.append(X[-1] - fn/fpn)
if abs(X[-1] - X[-2]) < tol:
return np.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return np.array(X)
else:
raise ValueError(msg)Let’s solve again so .
f = lambda x: x**3 - x - 2
fp = lambda x: 3*x**2 - 1
r = newton(f, fp, x0=1)
print("Approximate root:", r)
print("f(root) =", f(r))Approximate root: 1.5213797068045676
f(root) = 0.0
def tangent(f, fp, x0):
m = fp(x0)
return lambda x: f(x0) + m*(x - x0)
X = np.linspace(0.9, 2.1, 221)
Y = f(X)
R = newton(f, fp, 1, history=True)
plt.axhline(0, color="k", ls=":", lw=1)
plt.plot(X, Y, color="k", label="f(x)")
for n in range(len(R)-1):
plt.plot(R[n], f(R[n]), "o", label=f"Step {n}", color=f"C{n}")
plt.plot(X, tangent(f, fp, R[n])(X), color=f"C{n}")
plt.plot([R[n+1], R[n+1]], [0, f(R[n+1])], ":", color=f"C{n}")
plt.plot(R[-1], f(R[-1]), "o", label=f"Step {len(R)-1}", color=f"C{len(R)-1}")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.xlim(0.9, 2.1)
plt.ylim(-2.5, 4.5)
#plt.xlim( 1.5213, 1.5215)
#plt.ylim(-0.0005, 0.0005)
plt.legend()
plt.title("Newton–Raphson: tangent iteration")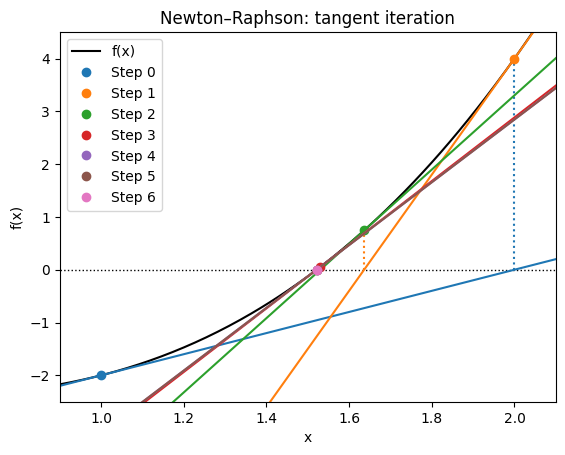
Let’s try different initial guesses:
for x0 in np.linspace(-5, 5, 11):
try:
R = newton(f, fp, x0, history=True)
print(f"Start {x0:.2f} -> root {R[-1]:.6f} in {len(R)} steps")
except Exception as e:
print(f"Failed: {e}; History: {R}")Start -5.00 -> root 1.521380 in 11 steps
Start -4.00 -> root 1.521380 in 20 steps
Start -3.00 -> root 1.521380 in 32 steps
Start -2.00 -> root 1.521380 in 31 steps
Start -1.00 -> root 1.521380 in 33 steps
Start 0.00 -> root 1.521380 in 32 steps
Start 1.00 -> root 1.521380 in 7 steps
Start 2.00 -> root 1.521380 in 6 steps
Start 3.00 -> root 1.521380 in 7 steps
Start 4.00 -> root 1.521380 in 8 steps
Start 5.00 -> root 1.521380 in 9 steps
Note that near the root 1.5, the convergence is very fast. Starting at 0.0 took many more steps and almost fails because it initially gives a poor direction. The Newton-Raphson method may actually diverge.
# HANDSON: try to provide a f() (and hence fp()) and x0 so that
# Newton-Raphson fails to converge.
# HINT: try f(x) = cos(x) - x
Newton-Raphson Method with Automatic Differentiation (by JAX)¶
Computing derivatives manually is tedious. With JAX, we can define only and let autodiff handle .
import jax
jax.config.update("jax_enable_x64", True)
import jax.numpy as jnp
from jax import grad, jit
def autonewton(f, x0, tol=1e-6, imax=100, history=False):
fp = jit(grad(f))
X = [float(x0)]
for _ in range(imax):
fn, fpn = f(X[-1]), fp(X[-1])
if fpn == 0:
raise ValueError("Derivative is zero: Newton step undefined.")
X.append(X[-1] - fn/fpn)
if abs(X[-1] - X[-2]) < tol:
return jnp.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(X)
else:
raise ValueError(msg)r = autonewton(f, x0=1)
print("Approximate root:", r)
print("f(root) =", f(r))Approximate root: 1.5213797068045676
f(root) = 0.0
Pros: extremely fast (quadratic convergence) when near the root.
Cons: requires derivative (not really a problem with autodiff), can fail with bad initial guess.
Best practice: combine with a robust method (e.g. start with bisection, then switch to Newton).
Newton-Raphson Method for Nonlinear Systems¶
So far, we have solved single equations . But in real applications, from orbital mechanics to stellar structure modeling, we often need to solve systems of nonlinear equations:
In multiple dimensions, we generalize Newton’s method by using the Jacobian matrix:
At each iteration, we solve the linear system:
and update:
This is the Newton–Raphson update for nonlinear systems.
def newton_system(F, J, X0, tol=1e-6, imax=100, history=False):
X = [np.array(X0, dtype=float)]
for _ in range(imax):
Fn = F(X[-1])
Jn = J(X[-1])
dX = np.linalg.solve(Jn, -Fn) # let numpy raise exception
X.append(X[-1] + dX)
if np.max(abs(X[-1] - X[-2])) < tol:
return np.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return np.array(X)
else:
raise ValueError(msg)Consider the system:
def F(X):
x, y = X
return np.array([
x**2 + y**2 - 4,
np.exp(x) + y - 1,
])
def J(X):
x, y = X
return np.array([
[2*x, 2*y],
[np.exp(x), 1.0],
])
X0 = [1.0, 1.0]
root = newton_system(F, J, X0)
print("Approximate root:", root)
print("F(root) =", F(root))Approximate root: [-1.81626407 0.8373678 ]
F(root) = [3.81028542e-13 2.57571742e-14]
Newton-Raphson Systems with Automatic Jacobian (by JAX)¶
In higher dimensions, computing derivatives by hand is even more tedious. We can use JAX autodiff to generate the Jacobian automatically.
from jax import jacfwddef autonewton_system(F, X0, tol=1e-6, imax=100, history=False):
J = jacfwd(F)
X = [jnp.array(X0, dtype=float)]
for _ in range(imax):
Fn = F(X[-1])
Jn = J(X[-1])
dX = np.linalg.solve(Jn, -Fn) # let numpy raise exception
X.append(X[-1] + dX)
if np.max(abs(X[-1] - X[-2])) < tol:
return jnp.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(X)
else:
raise ValueError(msg)def F(X):
x, y = X
return jnp.array([
x**2 + y**2 - 4,
jnp.exp(x) + y - 1,
])
X0 = [1.0, 1.0]
R = autonewton_system(F, X0)
print("Approximate root:", R)
print("F(root) =", F(R))Approximate root: [-1.81626407 0.8373678 ]
F(root) = [3.81028542e-13 2.57571742e-14]
Pros:
Quadratic convergence in multiple dimensions.
Works naturally with systems of equations.
Cons:
Requires solving a linear system at each step (costly for large ).
Fragile if the Jacobian is singular or if the initial guess is poor.
# HANDSON: Try modifying the system of equations to:
#
# f1(x,y) = sin(x) + y**2 - 1
# f2(x,y) = x**2 - y - 1
#
# Use both the hand-coded Jacobian and JAX autodiff.
# How many iterations are needed to converge from an initial
# guess [0.5, 0.5]?
Optimization Methods¶
We now turn from root finding to optimization.
At first, these may seem like different problems:
Root finding: Solve .
Optimization: Find that minimizes (or maximizes) .
But they are deeply connected. A critical point of a differentiable function occurs when the gradient vanishes:
Thus, optimization can often be reformulated as root finding on the gradient.
Some applications in astrophysics include:
The principle of least action states that nature chooses trajectories that extremize the action.
Fitting a model to data often requires minimizing a chi-square error function.
Training a neural network to classify galaxies is an optimization problem, i.e., minimizing a loss function over millions of parameters.
Gradient Descent in One Dimension¶
The most basic optimization algorithm is Gradient Descent. It is simple, intuitive, and forms the foundation of modern optimization in high dimensions.
Suppose we want to minimize a differentiable function .
The derivative points in the direction of steepest ascent.
Moving in the opposite direction reduces .
The update rule is:
where is the “learning rate” or “step size”.
def gd(fp, x0, alpha, tol=1e-6, imax=100, history=False):
X = [float(x0)]
for _ in range(imax):
X.append(X[-1] - alpha * fp(X[-1]))
if abs(X[-1] - X[-2]) < tol:
return np.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return np.array(X)
else:
raise ValueError(msg)f = lambda x: (x-3)**2 + 4
fp = lambda x: 2*(x-3)x0 = 0.0
alpha = 0.1
Xmin = gd(fp, x0, alpha, history=True)
print("Approximate minimum:", Xmin[-1])
print("f(xmin) =", f(Xmin[-1]))Approximate minimum: 2.9999963220107015
f(xmin) = 4.000000000013528
X = np.linspace(-0.5, 3.5, 401)
Y = f(X)
plt.plot(X, Y, label="f(x)")
plt.plot(Xmin, f(Xmin), "o--", label="GD steps")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend()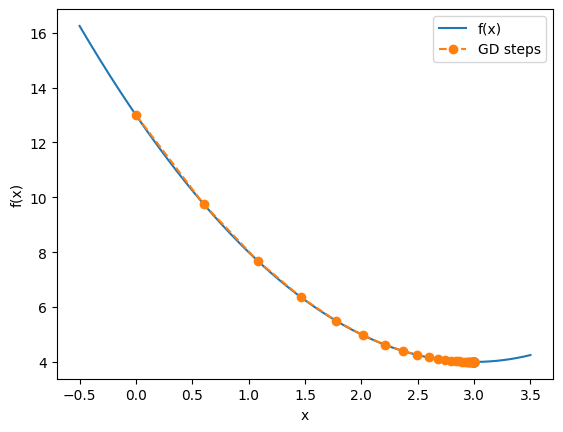
# HANDSON: Change `x0` and `alpha` and monitor how many steps are
# needed to obtain the solution.
# What is the optimal choice of `alpha`?
# NOTE: You may need to adjust the axis limits.
From the hands-on, we saw:
If is too small, convergence is very slow.
If is too large, the algorithm may overshoot and even diverge.
With a well-chosen , the iteration converges smoothly to the minimum.
This trade-off between stability and speed is central to all gradient-based optimization.
Compared gradient descent with Newton-Raphson method, there are few interesting observations:
Newton-Raphson requires function evaluation but not learning rate . Gradient descent is the opposite.
Both of them use fix point iterations:
If we consider gradient descent as root finding for , then Newton-Raphson becomes
Comparing this to gradient descent, we have , which makes sense because only when is near its minimum.
If we consider so , then gradient descent becomes
Comparing this to Newton-Raphson, we have .
Although gradient descent only needs but not , very often still take a simplier form to write. In such a case, using autodiff can be handly.
def autogd(f, x0, alpha, tol=1e-6, imax=100, history=False):
fp = jit(grad(f))
X = [float(x0)]
for _ in range(imax):
X.append(X[-1] - alpha * fp(X[-1]))
if abs(X[-1] - X[-2]) < tol:
return jnp.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(X)
else:
raise ValueError(msg)x0 = 0.0
alpha = 0.1
Xmin = autogd(f, x0, alpha, history=True)
print("Approximate minimum:", Xmin[-1])
print("f(xmin) =", f(Xmin[-1]))Approximate minimum: 2.9999963220107015
f(xmin) = 4.000000000013528
X = np.linspace(-0.5, 3.5, 401)
Y = f(X)
plt.plot(X, Y, label="f(x)")
plt.plot(Xmin, f(Xmin), "o--", label="GD steps")
plt.xlabel("x")
plt.ylabel("f(x)")
plt.legend()# HANDSON: solve a root finding problem using gradient descent.
# Does it work better or worse?
# HANDSON: solve a minimization problem using root finding.
# Does it work better or worse?
Gradient Descent in Multiple Dimensions¶
Most optimization problems in science and engineering are multidimensional. I.e., we need to minimize a function of several variables:
Gradient descent naturally general to these problems because the gradient vector still points in the direction of steepest ascent.
Again, to minimize , we simply move in the opposite direction:
where is the learning rate.
In fact, for multidimensional problems, very often has
a simplier form than .
Let’s update our autodg() for multidimensional problems then:
def autogd(f, X0, alpha, tol=1e-6, imax=100, history=False):
Gf = jit(grad(f))
X = [jnp.array(X0, dtype=float)]
for _ in range(imax):
X.append(X[-1] - alpha * Gf(X[-1]))
if np.max(abs(X[-1] - X[-2])) < tol:
return jnp.array(X) if history else X[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(X)
else:
raise ValueError(msg)Consider a simple quadratic bowl:
which has a unique minimum at . This function is smooth, convex, and easy to visualize.
# Define the function
def f(X):
x, y = X
return (x - 3)**2 + 2*(y + 4)**2X0 = [0.0, 0.0] # initial guess
alpha = 0.1 # learning rate
Xmin = autogd(f, X0, alpha, history=True)print("Approximate minimum:", Xmin[-1])
print("f(xmin) =", f(Xmin[-1]))Approximate minimum: [ 2.99999632 -4. ]
f(xmin) = 1.3527605279558334e-11
X = np.linspace(-2, 8, 201)
Y = np.linspace(-9, 1, 201)
X, Y = np.meshgrid(X, Y)
Z = f((X, Y))
plt.contour(X, Y, Z, levels=20)
plt.plot(Xmin[:,0], Xmin[:,1], "ro--", label="GD path")
plt.gca().set_aspect("equal")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()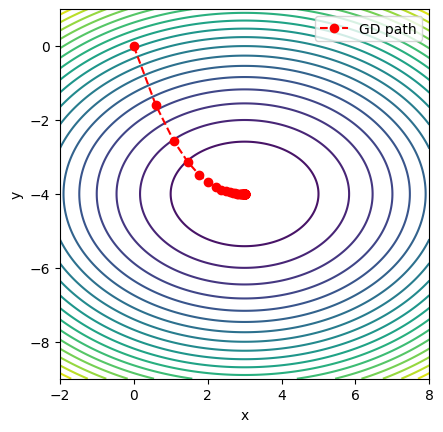
We can also track the loss function (objective value) as a function of iteration:
L = [f(X) for X in Xmin]
plt.semilogy(L, "o-")
plt.xlabel("Iteration")
plt.ylabel("f(x,y)")
plt.title("Convergence of Gradient Descent")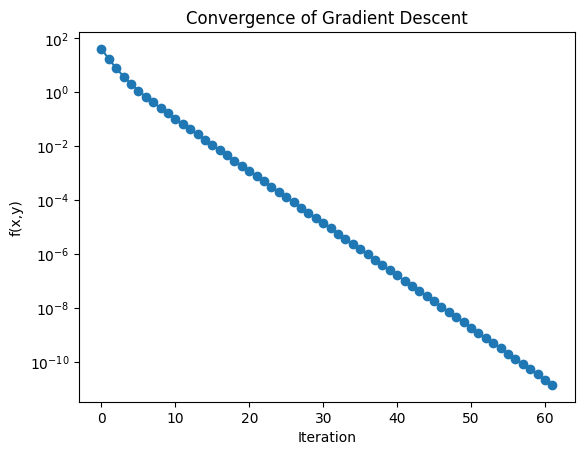
This 2D example illustrates how gradient descent generalizes naturally from 1D. In practice, astrophysics and machine learning involve thousands or millions of parameters. The same principle applies: take small steps downhill, guided by the gradient.
# HANDSON: try using gradient descent on more complicated functions.
Stochastic Gradient Descent (SGD)¶
Simple gradient descent works well for simple functions. But in practice, especially in machine learning and large-scale astrophysical modeling, we often minimize functions defined as averages over huge datasets:
where:
are the model parameters,
is the loss for a single data point,
is the dataset size (millions or more).
Computing the full gradient requires looping over all points each step, which can be very slow.
Instead of using all data points at each step, the idea of stochastic gradient descent (SGC) is to approximate the gradient using a random subset (i.e., a mini-batch):
where . This reduces computation per step and introduces randomness that can help escape local minima.
To develop a SGC algorithm, it is useful to start with an example. Let’s generate noisy data from a degree-6 polynomial, then fit it by minimizing the mean squared error with SGD.
Ptrue = np.array([1.2, -3, 0.5, 1.0, -1.8, 2.0, -0.1])
Xdata = np.linspace(-1, 1, 1000)
Ytrue = sum(c * Xdata**i for i, c in enumerate(Ptrue))
Ydata = Ytrue + np.random.normal(scale=0.1, size=Xdata.shape)
plt.plot(Xdata, Ytrue, label="True polynomial")
plt.plot(Xdata, Ydata, ".", alpha=0.3, label="Noisy data")
plt.legend()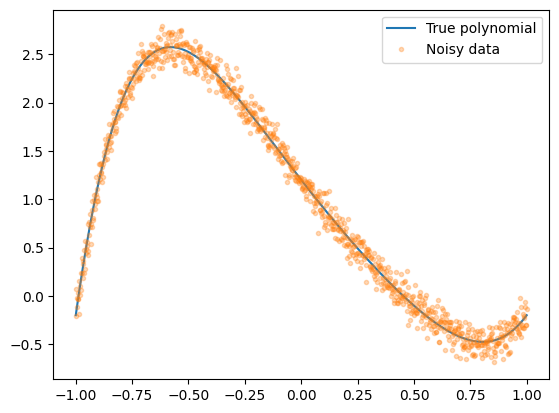
Next, let’s define model and loss function.
def model(P, X):
return sum(c * X**i for i, c in enumerate(P))
def mse(P, X, Y):
return jnp.mean((model(P, X) - Y)**2)And then modify our autogd() function to become sgd().
The usual applications of SGD have many parameters.
It is unlikely that we will provide gradient manually.
Let’s just drop the auto in its name.
from tqdm import tqdm
def sgd(f, P0, X, Y, alpha, B=10, tol=1e-6, imax=100, history=False):
assert len(X) == len(Y)
Gf = jit(grad(f))
N = len(X)
P = [jnp.array(P0, dtype=float)]
for _ in tqdm(range(imax)):
# Random mini-batch
I = np.random.choice(N, N//B, replace=False)
Xb, Yb = X[I], Y[I]
P.append(P[-1] - alpha * Gf(P[-1], Xb, Yb))
if np.max(abs(P[-1] - P[-2])) < tol:
return jnp.array(P) if history else P[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(P)
else:
raise ValueError(msg)P0 = jnp.zeros(len(Ptrue)) # initial guess
alpha = 0.1
B = 100
P = sgd(mse, P0, Xdata, Ydata, alpha, B=B, tol=1e-3, imax=1000, history=True)
print("Final coefficients (SGD):", P[-1])
print("True coefficients:", Ptrue) 53%|████████████████████▋ | 532/1000 [00:00<00:00, 697.48it/s]Final coefficients (SGD): [ 1.25281536 -2.94518085 -0.12024169 0.98787108 -0.59063657 1.91408584
-0.70557072]
True coefficients: [ 1.2 -3. 0.5 1. -1.8 2. -0.1]
Before looking at the fit, we can look at the loss function, which is just the MSE.
L = [mse(Pn, Xdata, Ydata) for Pn in P]
plt.semilogy(L, "o-")
plt.xlabel("Iteration")
plt.ylabel("MSE Loss")
plt.title("SGD Convergence")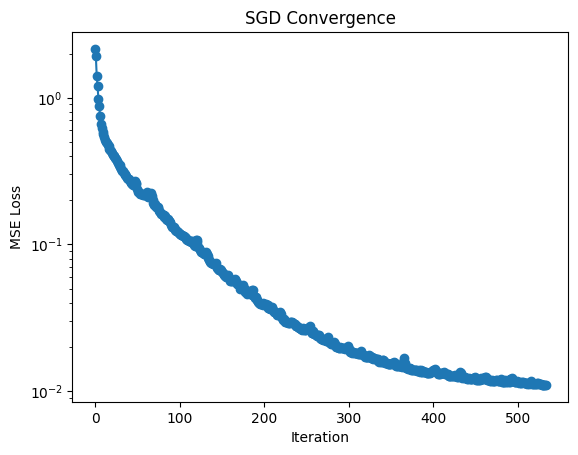
We can now plot the fit.
Yfit = model(P[-1], Xdata)
plt.plot(Xdata, Ytrue, label="True polynomial")
plt.plot(Xdata, Ydata, ".", alpha=0.3, label="Noisy data")
plt.plot(Xdata, Yfit, "--", label="SGD fit")
plt.legend()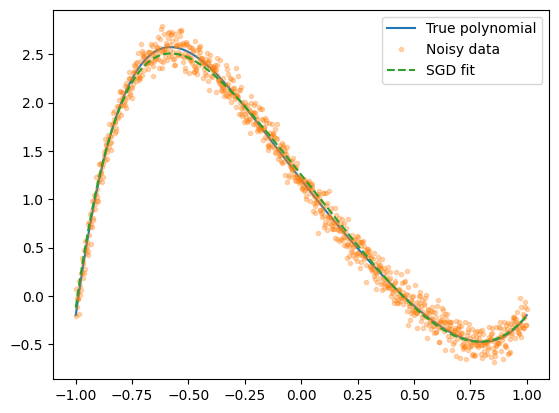
# HANDSON: try different number of batch and study the convergence
# properties of SGD.
# HANDSON: use `%timeit` to check performance.
# Do you get the answer faster if you set B=1 but use less
# number of iteration?
Pros:
Much faster per step for large datasets.
Handles huge data by working with small batches.
Noise in updates can help escape local minima.
Cons:
More noisy convergence compared to full-batch gradient descent.
Requires tuning of batch size and learning rate.
Often combined with enhancements (e.g., momentum, Adam optimizer).
The Adam Optimizer¶
SGD is powerful but has limitations:
Sensitive to the choice of learning rate.
Convergence can be slow if the landscape is poorly scaled.
Updates can oscillate in narrow valleys of the loss function.
The Adam (Adaptive Moment Estimation) optimizer improves on SGD by combining two ideas:
Momentum: Smooth the updates by averaging past gradients.
Adaptive Learning Rates: Scale each parameter’s step size individually based on gradient magnitudes.
Introduced by Kingma & Ba (2014), Adam has become the default optimizer in machine learning.
At each step :
Compute gradient:
Update biased first moment (exponential moving average of gradients):
Update biased second moment (exponential moving average of squared gradients):
Apply bias correction:
Update parameters:
Default parameters: , , .
def adam(f, P0, X, Y, alpha,
beta1=0.9, beta2=0.999, epsilon=1e-8, B=10,
tol=1e-6, imax=100, history=False):
assert len(X) == len(Y)
Gf = jit(grad(f))
N = len(X)
P = [jnp.array(P0, dtype=float)]
M, V = 0, 0
for n in tqdm(range(imax)):
# Random mini-batch
I = np.random.choice(N, N//B, replace=False)
Xb, Yb = X[I], Y[i]
# Adam algorithm
G = Gf(P[-1], X, Y)
M = beta1 * M + (1 - beta1) * G
V = beta2 * V + (1 - beta2) * G*G
Mh = M / (1 - beta1**(n+1))
Vh = V / (1 - beta2**(n+1))
P.append(P[-1] - alpha * Mh / (jnp.sqrt(Vh) + epsilon))
if np.max(abs(P[-1] - P[-2])) < tol:
return jnp.array(P) if history else P[-1]
msg = "Maximum iterations reached without convergence"
if history:
from warnings import warn
warn(msg)
return jnp.array(P)
else:
raise ValueError(msg)P0 = jnp.zeros(len(Ptrue)) # initial guess
alpha = 0.1
B = 100
P = adam(mse, P0, Xdata, Ydata, alpha, B=B, tol=1e-3, imax=500, history=True)
print("Final coefficients (Adam):", P[-1])
print("True coefficients:", Ptrue) 27%|██████████▊ | 135/500 [00:00<00:01, 223.56it/s]Final coefficients (Adam): [ 1.21726515 -2.90937222 0.10441762 0.63294315 -0.67205546 2.30960501
-0.89512215]
True coefficients: [ 1.2 -3. 0.5 1. -1.8 2. -0.1]
L = [mse(Pn, Xdata, Ydata) for Pn in P]
plt.semilogy(L, "o-")
plt.xlabel("Iteration")
plt.ylabel("MSE Loss")
plt.title("Adam Convergence")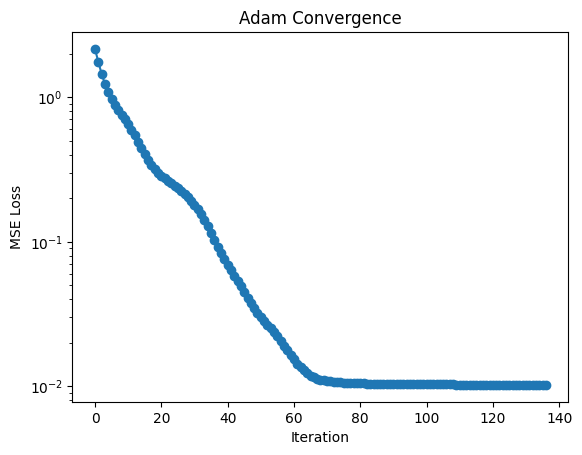
Yfit = model(P[-1], Xdata)
plt.plot(Xdata, Ytrue, label="True polynomial")
plt.plot(Xdata, Ydata, ".", alpha=0.3, label="Noisy data")
plt.plot(Xdata, Yfit, "--", label="SGD fit")
plt.legend()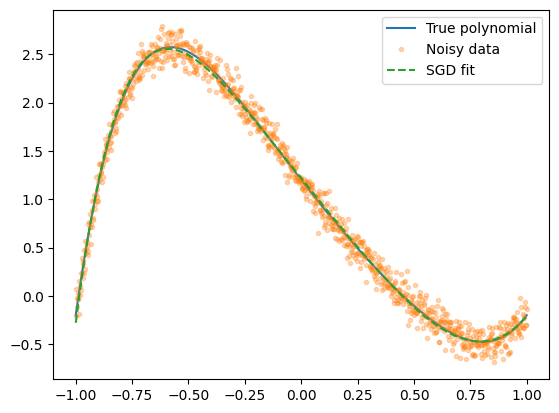
# HANDSON: try different number of batch and study the convergence
# properties of Adam.
# HANDSON: use `%timeit` to check performance.
# Do you get the answer faster if you set B=1 but use less
# number of iteration?
Pros:
Adapts learning rates automatically.
Handles noisy or sparse gradients well.
Faster and more stable than plain SGD in practice.
Cons:
Can sometimes fail to converge to the true minimum (over-adaptation).
Still requires some hyperparameter tuning.
Despite this, Adam is often the go-to optimizer in deep learning and large-scale scientific applications.