In science and engineering, many important quantities are obtained by integrating functions. Examples include the total energy radiated by a star (integral of brightness over wavelength), the probability of finding a quantum particle in a region (integral of probability density), or the synchrotron emissivity function (integral over electron distribution function).
Analytical solutions are rare because real functions often come from measurements, simulations, or complicated models. In such cases, we rely on numerical integration (or quadrature) to approximate
using only a finite number of function evaluations.
Numerical integration provides a controlled setting to study how approximations are constructed, how accuracy depends on step size, and how errors accumulate. These lessons generalize directly to solving differential equations and more complex simulations, making integration an essential starting point for good numerical practice.
To study numerical integration systematically, it helps to begin with a function whose integral we know exactly. Consider . Its definite integral from to is
On the interval , the exact value is . This known result will allow us to check the accuracy of numerical approximations as we vary step size and method.
Below is a simple plot of on for visual reference.
import numpy as np
def f(x):
return np.exp(x)
# Define a fine grid for plotting
X = np.linspace(0, 1, 1025)
Y = f(X)import matplotlib.pyplot as plt
plt.plot(X, Y, label=r"$f(x) = e^x$")
plt.fill_between(X, Y, alpha=1/3, label=r'$I = \int_a^b f(x) dx$')
plt.title(r'Function $f(x) = e^x$ on $[0,1]$')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend()
Riemann Sums¶
In undergraduate calculus, we learn the integral as the limit of Riemann sums:
where .
In numerical analysis, however, we do not take the limit. Instead, we keep the division of into subintervals and use
as a practical approximation. The choice of sampling point determines the accuracy.
Common choices for give us three variants:
Left Riemann Sum: is the left endpoint.
Right Riemann Sum: is the right endpoint.
Midpoint (or middle) Riemann Sum: is the midpoint.
n = 8 # number of intervals
dx = 1 / n
Xl = np.linspace(0, 1-dx, n)
Xm = np.linspace(dx/2, 1-dx/2, n)
Xr = np.linspace(dx, 1, n)fig, axes = plt.subplots(1,3, figsize=(12,4), sharey=True)
# Left Riemann Sum
for ax, Xs, name in zip(axes, [Xl, Xm, Xr], ['Left', 'Middle', 'Right']):
Ys = f(Xs)
ax.plot(X, Y)
ax.bar(Xm, Ys, width=dx, align='center', color='C1', edgecolor=None, alpha=1/3)
ax.scatter(Xs, Ys, color='C1', zorder=10)
ax.set_title(f'{name} Riemann Sum')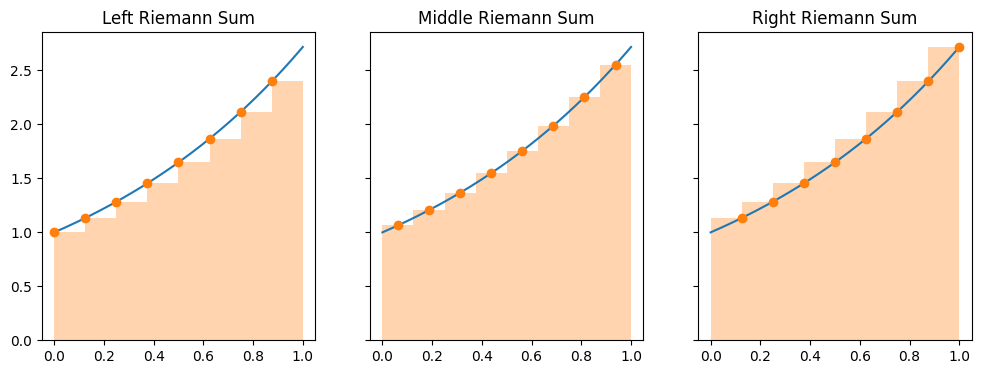
# HANDSON: There is another to define the middle Reimann sun,
# where the sample points are "on vertex ", i.e.,
# $x_i = a + (b-a) (i/n)$ for $i = 0, ..., n$.
# What is the different between this definition and ours?
# From the plots, what do you think about the relationships
# between left, right, and this new middle Reimann sums?
Computing Riemann Sums¶
Now that we have defined the left, right, and midpoint Riemann sums, let us implement them and check their accuracy against the exact result
We begin with a simple case using subintervals.
I = np.e - 1
print(f" Exact value: {I :.8f}")
for ax, Xs, name in zip(axes, [Xl, Xm, Xr], ['Left', 'Middle', 'Right']):
S = np.sum(f(Xs)) * dx # multiple dx after sum
print(f"{name:>8} Riemann Sum: {S:.8f}, error = {abs(I - S):.2e}") Exact value: 1.71828183
Left Riemann Sum: 1.61312598, error = 1.05e-01
Middle Riemann Sum: 1.71716366, error = 1.12e-03
Right Riemann Sum: 1.82791121, error = 1.10e-01
# HANDSON: try increasing $n$ and then observe the errors.
As the number of subintervals increases, all three Riemann sums converge toward the exact value . However, the midpoint rule generally gives much better accuracy for the same , just as central differences are more accurate than forward or backward differences. This shows how the choice of sample points directly affects accuracy.
Convergence of Riemann Sums¶
In numerical analysis, as we saw in earlier lecture, convergence means studying how the error decreases as we refine the discretization. For integration, we ask how does the error behave as we increase the number of subintervals ?
To make comparisons easier, let’s define a general function for computing Riemann sums of any type:
def RiemannSum(f, n=8, a=0, b=1, method='mid'):
dx = (b-a)/n
hx = dx/2
if method.startswith('l'):
X = np.linspace(a, b-dx, n) # left endpoints
elif method.startswith('r'):
X = np.linspace(a+dx, b, n) # right endpoints
else:
X = np.linspace(a+hx, b-hx, n) # midpoints
return np.sum(f(X)) * dxNow we can study convergence systematically by increasing .
def convergence(f, N, I):
# Compute absolute errors for each method
El = [abs(RiemannSum(f, n, method='l') - I) for n in N]
Em = [abs(RiemannSum(f, n, method='m') - I) for n in N]
Er = [abs(RiemannSum(f, n, method='r') - I) for n in N]
# Plot convergence behavior
plt.loglog(N, El, 'o-', label='Left Riemann Sum')
plt.loglog(N, Em, '^--', label='Middle Riemann Sum')
plt.loglog(N, Er, 's:', label='Right Riemann Sum')
# Reference slopes
plt.loglog(N, 1.2e+0 / N, ':', lw=1, label=r'$n^{-1}$')
plt.loglog(N, 1.0e-1 / N**2, ':', lw=1, label=r'$n^{-2}$')
plt.xlabel('Number of Subintervals $n$')
plt.ylabel('Absolute Error')
plt.title('Convergence of Riemann Sums')
plt.legend()N = 2**np.arange(2,11) # range of sample sizes
convergence(f, N, np.e-1)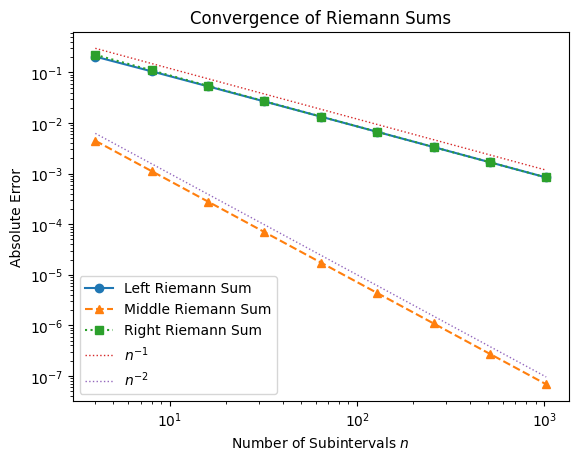
From the plot, we observe:
Left and Right Riemann sums converge at roughly a rate .
Midpoint Riemann sum converges faster, at a rate closer to .
This higher order of accuracy explains why the midpoint method is much more accurate for the same number of intervals. The pattern mirrors what we saw with finite differences: forward and backward methods are first-order accurate, while central methods are second-order accurate.
Testing Convergence with Different Functions¶
To determine if this trend holds generally, let’s repeat the convergence test with different functions: a half-cycle of and a quarter circle .
f2 = lambda x: np.sin((np.pi/2) * (1-x))
f3 = lambda x: np.sqrt(1 - x*x)
plt.plot(X, f2(X))
plt.plot(X, f3(X))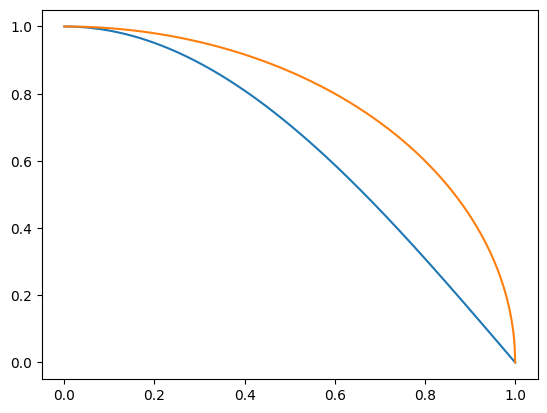
convergence(f2, N, 2/np.pi)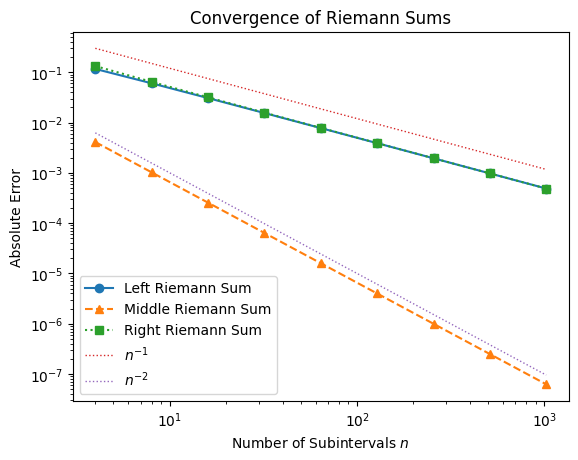
convergence(f3, N, np.pi/4)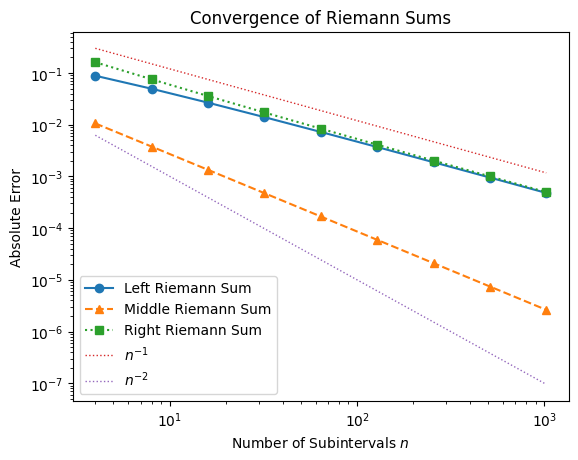
# HANDSON: why does Middle Riemann Sum not converge as expected for
# quarter circle?
Although the formal convergence rates hold in general, special functions (e.g. highly oscillatory or discontinuous ones) may behave differently. Understanding these exceptions is a key part of numerical analysis.
As we progress, we will adopt the notation and framework used in Numerical Recipes and related references. These general-purpose methods extend the ideas of Riemann sums to more accurate and flexible quadrature formulas, allowing us to tackle realistic integration problems efficiently.
Classical Formulas for Equally Spaced Abscissas¶
Trapezoidal Rule¶
To move beyond Riemann sums, we now consider the trapezoidal rule, one of the most widely used numerical integration formulas.
From here on, we adopt the vertex formulation:
The trapezoidal rule approximates the area under a curve by replacing each subinterval with a trapezoid. For a single interval with width , we have:
The error for one interval is of order , which means the global error (after intervals) is . This makes the trapezoidal rule second-order accurate. If is linear (so ), the approximation is exact.
# Test function: quarter circle
Y = f(X)
# Plot with a coarse trapezoidal partition
n = 4
Xt = np.linspace(0, 1, n+1)
Yt = f(Xt)
plt.plot(X, Y, label=r"$f(x) = \sqrt{1-x^2}$")
plt.scatter(Xt, Yt, color='C1')
plt.bar(Xt, Yt, width=Xt[1]-Xt[0], align='center',
color='C1', edgecolor=None, alpha=1/3, label='Middle Riemann Sum')
plt.fill_between(Xt, Yt,
color='C2', alpha=1/3, label='Trapezoidal Rule')
plt.xlim(0, 1)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.legend()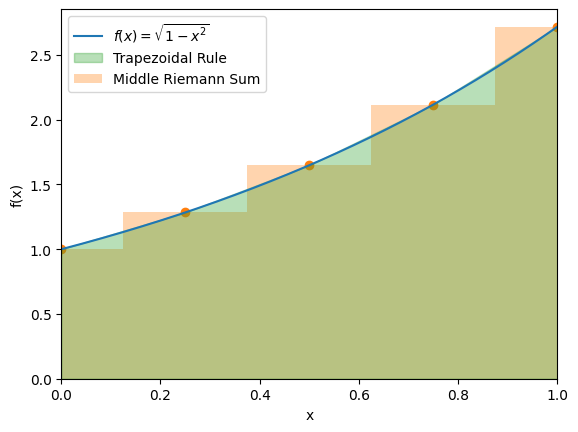
def trapezoidal(f, n=8, a=0, b=1):
"""Trapezoidal rule integration of f from a to b using n intervals."""
X, dx = np.linspace(a, b, n+1, retstep=True)
return np.sum(f(X[:-1]) + f(X[1:])) * (dx/2)def convergence(f, N, I):
# Compute absolute errors for each method
El = [abs(RiemannSum (f, n, method='l') - I) for n in N]
Em = [abs(RiemannSum (f, n, method='m') - I) for n in N]
Er = [abs(RiemannSum (f, n, method='r') - I) for n in N]
Et = [abs(trapezoidal(f, n) - I) for n in N]
# Plot convergence behavior
plt.loglog(N, El, 'o-', label='Left Riemann Sum')
plt.loglog(N, Em, '^--', label='Middle Riemann Sum')
plt.loglog(N, Er, 's:', label='Right Riemann Sum')
plt.loglog(N, Et, 'x-', label='trapezoidal')
# Reference slopes
plt.loglog(N, 1.2e+0 / N, ':', lw=1, label=r'$n^{-1}$')
plt.loglog(N, 1.0e-1 / N**2, ':', lw=1, label=r'$n^{-2}$')
plt.xlabel('Number of Subintervals $n$')
plt.ylabel('Absolute Error')
plt.title('Convergence of Riemann Sums')
plt.legend()convergence(f, N, np.e-1)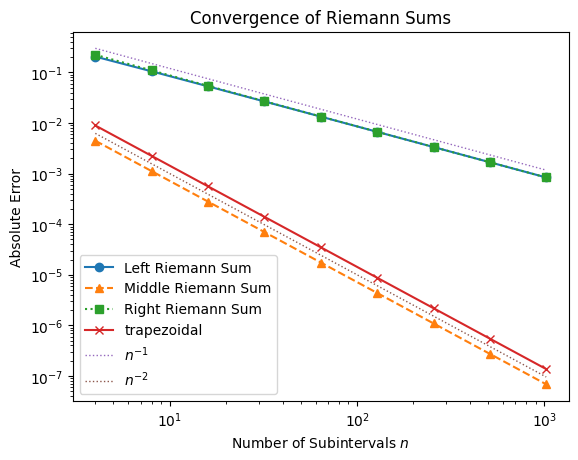
# HANDSON: use trapezoidal rule to integrate a linear equation
# HANDSON: use trapezoidal rule to integrate a qudratic equation
# HANDSON: look at the figure carefully.
# What is the result from the Middle Riemann Sum (on vertex)
# compared to the trapezoidal rule?
# HANDSON: reformulate the trapezoidal rule to speed it up.
%timeit trapezoidal(f, n=1024)35.6 μs ± 321 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Both the middle Riemann sum (midpoint rule) and the trapezoidal rule achieve second-order accuracy (). In fact, the trapezoidal rule is mathematically identical to the midpoint rule on vertices. However, the trapezoidal rule is often preferred because it naturally extends to more advanced methods (like Simpson’s rule and Romberg integration) and works well with non-smooth functions and tabulated data.
Integration vs. Differentiation¶
Before moving on to the next integration method, it is worth pausing to contrast numerical integration with finite differences for derivatives.
In finite differences, the operation is fundamentally local. For example, once we choose a central difference formula for , the approximation uses only a fixed number of sample points (two here). If we want higher accuracy, we can simply reduce the step size , but the number of function evaluations per derivative remains constant. This means that in practice, even a low-order difference formula can be made sufficiently accurate just by choosing a small (ignoring round-off error for now).
Integration is different. Approximating a definite integral requires covering the entire interval . As we reduce , we must add more sample points to span the domain. Thus, the cost of integration scales with accuracy. Halving would double the number of function evaluations for first-order methods like the left or right Riemann sums.
This difference makes the order of the integration method much more important.
With first-order schemes (Left/Right Riemann), each refinement improves accuracy slowly, so many function evaluations are needed.
With second-order schemes (Midpoint, trapezoidal), accuracy improves faster, but still grows in cost as decreases.
With higher-order schemes (like Simpson’s rule), we can achieve very accurate results with far fewer evaluations.
To summarize, for derivatives, low-order finite differences can often be “rescued” by shrinking . For integrals, low-order methods remain inefficient no matter how small is, because accuracy and cost is a trade-off. This is why higher-order integration rules are so valuable.
Simpson’s Rule¶
The trapezoidal rule is exact for linear functions. Naturally, we may ask: is there a method that is exact for quadratics? This leads us to Simpson’s rule, which integrates quadratic polynomials exactly.
There are many ways to derive the Simpson’s Rule. For simplicity, let’s “center” the integral at zero with limits . We approximate by a quadratic polynomial,
The integral becomes
To determine and , we use sample points:
Adding and gives
Substituting into the integral, we obtain
def SimpsonRule(f, n=8, a=0, b=1):
"""Simpson's rule integration of f from a to b using n intervals."""
X, dx = np.linspace(a, b, n+1, retstep=True)
S = 0
for i in range(n//2):
l = X[2*i]
m = X[2*i + 1]
r = X[2*i + 2]
S += (f(l) + 4*f(m) + f(r)) * (dx/3)
return Sdef convergence(f, N, I):
# Compute absolute errors for each method
El = [abs(RiemannSum (f, n, method='l') - I) for n in N]
Em = [abs(RiemannSum (f, n, method='m') - I) for n in N]
Er = [abs(RiemannSum (f, n, method='r') - I) for n in N]
Et = [abs(trapezoidal(f, n) - I) for n in N]
Es = [abs(SimpsonRule(f, n) - I) for n in N]
# Plot convergence behavior
plt.loglog(N, El, 'o-', label='Left Riemann Sum')
plt.loglog(N, Em, '^--', label='Middle Riemann Sum')
plt.loglog(N, Er, 's:', label='Right Riemann Sum')
plt.loglog(N, Et, 'x-', label='trapezoidal')
plt.loglog(N, Es, '+-', label="Simpson's Rule")
# Reference slopes
plt.loglog(N, 1.2e+0 / N, ':', lw=1, label=r'$n^{-1}$')
plt.loglog(N, 1.0e-1 / N**2, ':', lw=1, label=r'$n^{-2}$')
plt.loglog(N, 1.0e-1 / N**4, ':', lw=1, label=r'$n^{-4}$')
plt.xlabel('Number of Subintervals $n$')
plt.ylabel('Absolute Error')
plt.title('Convergence of Riemann Sums')
plt.legend()convergence(f, N, np.e-1)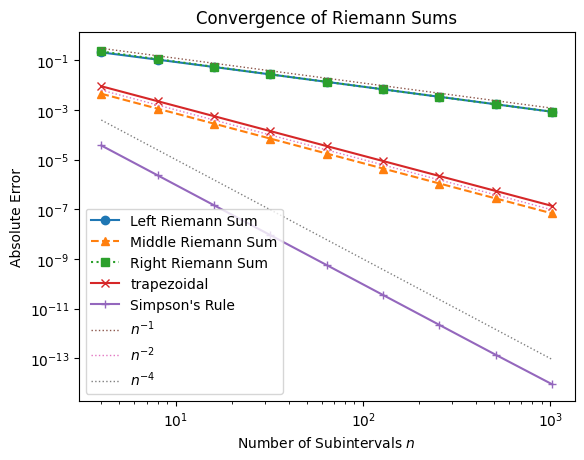
# HANDSON: use Simpson's rule to integrate a quadratic equation
# HANDSON: use Simpson's rule to integrate a cubic equation
# HANDSON: use Simpson's rule to integrate a 4th-order polynomial
Simpson’s rule fits a quadratic through three points, but its symmetry makes it exact for cubics as well. That means the first error term comes from the term in the Taylor expansion, which makes it fourth-order accurate.
# HANDSON: reformulate the Simpson's rule to speed it up.
Bode’s Rule¶
Simpson’s rule is exact for polynomials up to degree 3, giving fourth-order accuracy. If we want a rule that is exact for quartic polynomials, we can extend the idea. The next step in this family is Bode’s rule (sometimes called the 4th-order Newton-Cotes formula).
Bode’s rule uses five equally spaced points (four subintervals) and achieves sixth-order accuracy. The formula is:
where .
def BodeRule(f, n=8, a=0, b=1):
"""Bobe's rule integration of f from a to b using n intervals."""
X, dx = np.linspace(a, b, n+1, retstep=True)
S = 0
for i in range(n//4):
x0 = X[4*i]
x1 = X[4*i + 1]
x2 = X[4*i + 2]
x3 = X[4*i + 3]
x4 = X[4*i + 4]
S += (14*f(x0) + 64*f(x1) + 24*f(x2) + 64*f(x3) + 14*f(x4)) * (dx/45)
return Sdef convergence(f, N, I):
# Compute absolute errors for each method
El = [abs(RiemannSum (f, n, method='l') - I) for n in N]
Em = [abs(RiemannSum (f, n, method='m') - I) for n in N]
Er = [abs(RiemannSum (f, n, method='r') - I) for n in N]
Et = [abs(trapezoidal(f, n) - I) for n in N]
Es = [abs(SimpsonRule(f, n) - I) for n in N]
Eb = [abs(BodeRule (f, n) - I) for n in N]
# Plot convergence behavior
plt.loglog(N, El, 'o-', label='Left Riemann Sum')
plt.loglog(N, Em, '^--', label='Middle Riemann Sum')
plt.loglog(N, Er, 's:', label='Right Riemann Sum')
plt.loglog(N, Et, 'x-', label='trapezoidal')
plt.loglog(N, Es, '+-', label="Simpson's Rule")
plt.loglog(N, Eb, '|-', label="Bode's Rule")
# Reference slopes
plt.loglog(N, 1.2e+0 / N, ':', lw=1, label=r'$n^{-1}$')
plt.loglog(N, 1.0e-1 / N**2, ':', lw=1, label=r'$n^{-2}$')
plt.loglog(N, 1.0e-1 / N**4, ':', lw=1, label=r'$n^{-4}$')
plt.loglog(N, 1.0e-1 / N**6, ':', lw=1, label=r'$n^{-6}$')
plt.xlabel('Number of Subintervals $n$')
plt.ylabel('Absolute Error')
plt.title('Convergence of Riemann Sums')
plt.legend()convergence(f, N, np.e-1)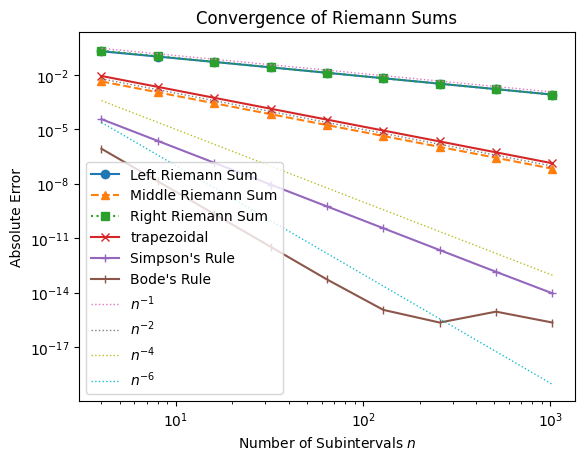
Both Simpson’s and Bode’s rules are part of the Newton-Cotes family of integration formulas. Their main advantage is that higher-order methods achieve much greater accuracy for the same number of function evaluations, which is especially valuable when each evaluation is costly. In practice, we see this in the error plots: while Simpson’s rule converges with , Bode’s rule converges even faster with and eventually saturates near 10-15, the limit of machine precision in double-precision arithmetic.
# HANDSON: reformulate the Bode's rule to speed it up.
Gaussian Quadrature¶
So far, our integration methods (Riemann sums, trapezoidal, Simpson’s, Bode’s) have all been part of the Newton–Cotes family. These methods use equally spaced points and approximate with a polynomial that passes through them.
Gaussian quadrature takes a different approach. Instead of fixing the points in advance, it chooses both the nodes and weights optimally so that the approximation
is exact for all polynomials up to degree , using only evaluations! This is far more efficient than Newton-Cotes formulas, which are exact only up to degree .
Step 1: Exactness for Polynomials¶
The above approximation has unknowns in total. They are nodes and weights . We demand that this formula be exact for all polynomials up to degree . That means:
This gives us conditions. exactly enough to determine the unknowns ( and ).
Step 2: Why Roots of Legendre Polynomials?¶
At this point, solving the nonlinear system directly would be messy. Instead, we use a trick:
Consider the -th Legendre polynomial .
It has distinct roots in .
Legendre polynomials are orthogonal:
Because of orthogonality, any polynomial of degree can be split into two parts:
A multiple of , which integrates to zero at the chosen nodes.
A lower-degree polynomial, which can be matched exactly by the quadrature formula.
This guarantees exactness up to degree .
Step 3: The Weights¶
Once the nodes are fixed (the roots of ), the weights can be computed. The closed form is
This ensures the quadrature works for all polynomials of degree up to .
Step 4: Change of Interval¶
Gaussian quadrature is naturally defined on . To apply it to an arbitrary interval , we transform:
which gives
def GQ(f, n=8, a=-1, b=1):
"""Gaussian quadrature integration of f over [a,b] using n points."""
# Nodes and weights for Legendre polynomial of degree n
X, W = np.polynomial.legendre.leggauss(n)
# Map nodes from [-1,1] to [a,b]
T = (a*(1-X) + b*(1+X))/2
# Weighted sum
return np.sum(W * f(T)) * (b-a)/2def convergence(f, N, I):
# Compute absolute errors for each method
El = [abs(RiemannSum (f, n, method='l') - I) for n in N]
Em = [abs(RiemannSum (f, n, method='m') - I) for n in N]
Er = [abs(RiemannSum (f, n, method='r') - I) for n in N]
Et = [abs(trapezoidal(f, n) - I) for n in N]
Es = [abs(SimpsonRule(f, n) - I) for n in N]
Eb = [abs(BodeRule (f, n) - I) for n in N]
Eg = [abs(GQ (f, n, 0, 1) - I) for n in N]
# Plot convergence behavior
plt.loglog(N, El, 'o-', label='Left Riemann Sum')
plt.loglog(N, Em, '^--', label='Middle Riemann Sum')
plt.loglog(N, Er, 's:', label='Right Riemann Sum')
plt.loglog(N, Et, 'x-', label='trapezoidal')
plt.loglog(N, Es, '+-', label="Simpson's Rule")
plt.loglog(N, Eb, '|-', label="Bode's Rule")
plt.loglog(N, Eg, '|-', label="Gaussian Quadrature")
# Reference slopes
plt.loglog(N, 1.2e+0 / N, ':', lw=1, label=r'$n^{-1}$')
plt.loglog(N, 1.0e-1 / N**2, ':', lw=1, label=r'$n^{-2}$')
plt.loglog(N, 1.0e-1 / N**4, ':', lw=1, label=r'$n^{-4}$')
plt.loglog(N, 1.0e-1 / N**6, ':', lw=1, label=r'$n^{-6}$')
plt.xlabel('Number of Subintervals $n$')
plt.ylabel('Absolute Error')
plt.title('Convergence of Riemann Sums')
plt.legend(loc='right')convergence(f, N, np.e-1)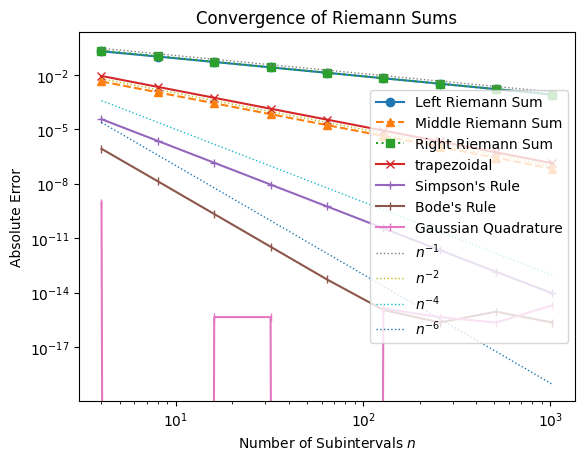
The Gaussian quadrature method converge extremely fast. With 8th-order approximation, its error is already less than machine accuracy. This makes it an ideal method to integrate smooth functions.
Handling Improper Integrals with Coordinate Transformation¶
So far, we have focused on integrals over finite intervals with smooth integrands. But many important problems involve improper integrals, such as those extending to infinity or with singularities at the endpoints. Classical Newton-Cotes formulas and Gaussian quadrature cannot be applied directly in these cases, because the domain is unbounded or the function diverges.
As an example, consider the integral
whose exact value is well-known .
Standard quadrature fails here, since the domain extends to infinity. The solution is to perform a coordinate transformation that maps the infinite domain to a finite interval.
A common substitution is
Differentiating,
Substituting into the integral gives
Simplifying,
Now the infinite limit is mapped to the finite limit . This transformed integral can be handled efficiently using trapezoidal, Simpson’s, Bode’s, or Gaussian quadrature.
# HANDSON: Implement the above transformed equation and integrate it
# numerically.
# Use `convergence()` to check its convergence property.
By carefully choosing coordinate transformations, we can extend high-order quadrature methods to improper integrals. This strategy will also be important for dealing with singular integrands, where direct endpoint evaluation fails.
Using SciPy and SymPy¶
In practice, you will rarely implement numerical integration formulas (Riemann sums, trapezoidal, Simpson’s, etc.) by hand in research projects. Instead, you will rely on well-tested libraries that provide efficient and accurate integrators.
SciPy offers a collection of state-of-the-art numerical integrators suitable for most scientific applications.
SymPy provides tools for symbolic integration, which can return exact formulas when they exist.
Numerical Integration with SciPy¶
The function scipy.integrate.quad() is a general-purpose adaptive
integrator.
It automatically refines sampling points until the estimated error is
within tolerance.
from scipy.integrate import quad
# Example: quarter circle integral (area of a quarter unit circle)
res, err = quad(f3, 0, 1)
print("Exact value (π/4):", np.pi/4)
print("Result:", res)
print("Estimated error:", err)Exact value (π/4): 0.7853981633974483
Result: 0.7853981633974481
Estimated error: 8.833911380179416e-11
Symbolic Integration with SymPy¶
When the integral has a closed-form expression, sympy can find it exactly. This is especially useful for validation, teaching, or algebraic manipulations.
from sympy import Symbol, integrate, sqrt, pi
x = Symbol('x')
# Indefinite integral
expr = integrate(sqrt(1 - x**2), x)
print("Indefinite integral:", expr)
# Definite integral from 0 to 1
res = integrate(sqrt(1 - x**2), (x, 0, 1))
print("Exact value (π/4):", pi/4)
print("Definite integral:", res, "~", float(res))Indefinite integral: x*sqrt(1 - x**2)/2 + asin(x)/2
Exact value (π/4): pi/4
Definite integral: pi/4 ~ 0.7853981633974483
In real workflows, you may combine both: use SymPy to derive formulas where possible, and fall back on SciPy when symbolic methods fail or when dealing with data-driven functions.
Final Comments¶
Increasing the order of approximation greatly improves accuracy. Higher-order methods (Simpson’s, Bode’s) converge much more rapidly than first-order rules (left/right Riemann).
For smooth functions, methods like Gaussian quadrature achieve even faster, often exponential, convergence.
Symbolic integration (e.g., with
sympy) can provide exact results when closed forms exist, and serves as a useful complement to numerical methods.For non-smooth functions (with discontinuities), the convergence rate drops to first order, regardless of the method. In such cases, refining the mesh near the discontinuity is the only way to recover accuracy.