Derivatives are fundamental in mathematical modeling because they quantify rates of change. They provide insight into how physical systems evolve, how signals vary, and how models respond to inputs.
In computational physics, engineering, and machine learning, the efficient and accurate computation of derivatives is essential. We rely on derivatives for simulations, optimization, and sensitivity analysis.
For simple functions, derivatives can often be computed analytically. But in real applications, functions are frequently nonlinear, high-dimensional, or too complex for manual differentiation. In these cases, alternative computational techniques become indispensable.
Definition of the Derivative¶
The derivative of a real-valued function at a point is defined as the limit
If this limit exists, it represents the slope of the tangent line to the curve at . More generally, the derivative function describes the local rate of change of .
Chain Rule¶
One of the most important rules in calculus is the chain rule. For a composite function ,
The chain rule is not just a basic calculus identity. It is the central principle behind modern computational approaches to derivatives. As we will see, both numerical differentiation schemes and automatic differentiation rely heavily on repeated applications of this rule.
Approaches to Computing Derivatives¶
There are three main approaches to computing derivatives in practice:
Symbolic differentiation Applies algebraic rules directly to mathematical expressions, producing exact formulas. (This is what you do in calculus class.)
Numerical differentiation Uses finite differences to approximate derivatives from discrete function values. These methods are easy to implement but introduce truncation and round-off errors.
Automatic differentiation (AD) Systematically applies the chain rule at the level of elementary operations. AD computes derivatives to machine precision without symbolic algebra, making it efficient for complex functions and large-scale systems.
Symbolic Differentiation¶
Symbolic differentiation computes derivatives by applying calculus rules directly to symbolic expressions. Unlike numerical methods that we will see later, which only approximate derivatives at specific points, symbolic methods yield exact analytical expressions. This makes them valuable for theoretical analysis, closed-form solutions, and precise computation.
The basic algorithm for symbolic differentiation can be described in three steps:
Parse the expression: Represent the function as a tree (nodes are operations like
+,*,sin, etc.).Apply differentiation rules: Recursively apply rules (e.g., product rule, chain rule) to each node.
Simplify: Reduce the resulting expression into a cleaner, more efficient form.
Consider the function . To compute , a symbolic differentiation system would:
Differentiate using the product rule:
Differentiate using the chain rule:
Combine the results:
Symbolic Differentiation with SymPy¶
We can use SymPy, a Python library for symbolic mathematics, to automate this process.
!pip install sympyRequirement already satisfied: sympy in /Users/ckc/.venv/teach/lib/python3.13/site-packages (1.14.0)
Requirement already satisfied: mpmath<1.4,>=1.1.0 in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from sympy) (1.3.0)
import sympy as sp
# Define symbolic variable and function
x = sp.symbols('x')
f = x**2 * sp.sin(x) + sp.exp(2*x)
# Differentiate
fp = sp.diff(f, x)
# Simplify result
fp_simplified = sp.simplify(fp)
# Display the result with equation support
display(f)
display(fp_simplified)SymPy can compute higher-order derivatives just as easily:
fpp = sp.diff(f, x, 2) # second derivative
fppp = sp.diff(f, x, 3) # third derivative
fpp_simplified = sp.simplify(fpp)
fppp_simplified = sp.simplify(fppp)
display(fpp_simplified)
display(fppp_simplified)We can visualize the function and its derivatives:
import numpy as np
# Convert sympy expression into numpy-callable functions
f_num = sp.lambdify(x, f, "numpy")
fp_num = sp.lambdify(x, fp_simplified, "numpy")
fpp_num = sp.lambdify(x, fpp_simplified, "numpy")
fppp_num = sp.lambdify(x, fppp_simplified, "numpy")import matplotlib.pyplot as plt
X = np.linspace(-1, 1, 101)
plt.plot(X, f_num(X), label=r'$f(x)$')
plt.plot(X, fp_num(X), label=r"$f'(x)$")
plt.plot(X, fpp_num(X), label=r"$f''(x)$")
plt.plot(X, fppp_num(X), label=r"$f'''(x)$")
plt.legend()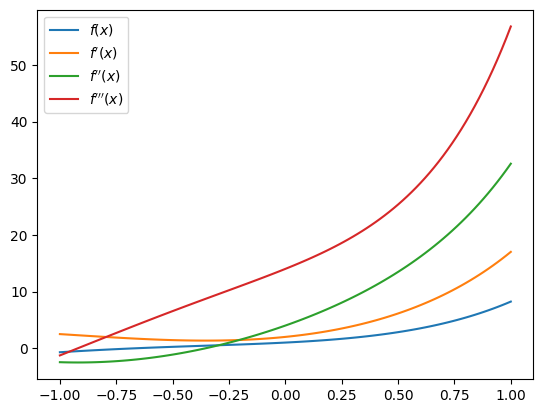
Pros and Cons¶
Symbolic differentiation is useful because it provides:
Exact results: no approximation or rounding errors (until it is evaluated with floating point numbers).
Validity across the domain: derivative formulas apply everywhere the function is defined.
Analytical insight: exact expressions make it easier to solve ODEs, optimize functions, and manipulate formulas algebraically.
Symbolic differentiation also has important drawbacks:
Expression growth: formulas can quickly become large and messy for complex functions.
Computational cost: evaluating or simplifying derivatives can be expensive for high-dimensional systems.
Limited applicability: not suitable when functions are given only by data, simulations, or black-box algorithms.
In such cases, numerical or automatic differentiation is usually the better choice.
Software Tools¶
Symbolic differentiation is supported in many systems:
SymPy: An open-source Python library that provides capabilities for symbolic differentiation, integration, and equation solving within the Python ecosystem.Mathematica: A computational software developed by Wolfram Research, offering extensive symbolic computation features used widely in academia and industry.Maple: A software package designed for symbolic and numeric computing, providing powerful tools for mathematical analysis.Maxima: An open-source computer algebra system specializing in symbolic manipulation, accessible for users seeking free alternatives.
# HANDSON: Differentiate and Simplify
#
# Define f(x) = ln(x^2 + 1) exp(x).
# Use SymPy to compute f'(x), simplify it, and plot both
# f(x) and f'(x).
# HANDSON: Product of Many Functions
#
# Define f(x) = sin(x) cos(x) tan(x).
# Compute derivatives up to order 3.
# What happens to expression complexity?
Finite Difference Methods¶
Numerical differentiation estimates the derivative of a function using discrete data points. Instead of exact formulas, it provides approximate values that are especially useful when analytical derivatives are difficult or impossible to obtain. This flexibility makes numerical methods essential for handling complex, empirical, or high-dimensional functions that appear in scientific and engineering applications.
The most common numerical approach is the finite difference method, which estimates derivatives by evaluating the function at nearby points and forming ratios of differences. These methods are simple to implement and widely used in practice. The key idea is to approximate the derivative by sampling the function at points around . The three elementary finite difference formulas are forward difference, backward difference, and central difference.
Forward Difference¶
The forward difference uses the function values at and :
This method is easy to implement. Assuming is already available, it requires only one extra function evaluation. However, it introduces a truncation error of order . While decreasing improves accuracy, making too small causes floating-point round-off errors to dominate.
Backward Difference¶
The backward difference uses values at and :
This has the same truncation error of order as the forward method. It is particularly useful when values of are unavailable or expensive to compute.
Central Difference¶
The central difference combines forward and backward differences to achieve higher accuracy:
This method has a truncation error of order , making it significantly more accurate for smooth functions. The trade-off is that it requires two extra function evaluations (not at ) instead of one, but the improved accuracy often makes it the preferred method.
Truncation Error vs. Round-Off Error¶
Finite difference methods must balance two sources of error:
Truncation error comes from approximating the derivative using a discrete difference.
Round-off error comes from the finite precision of floating-point arithmetic.
For forward and backward differences, truncation error decreases linearly with . For central differences, it decreases quadratically, giving better accuracy for small .
However, if becomes too small, round-off error dominates because the difference may be nearly indistinguishable in floating-point representation. Hence, we may be facing catastrophic cancellation as before.
The optimal choice of balances these two errors. A common rule of thumb is to set
where is the machine epsilon that we learned before. I.e., the smallest number such that in floating-point arithmetic.
Sample Codes¶
Below we implement the three basic finite-difference formulas (forward, backward, and central) and demonstrate their behavior on a smooth test function. We will also run a convergence study to see how truncation error (improves as goes smaller) and round-off error (gets worse as goes smaller) trade off in practice.
# Test function and its exact derivative
f = lambda x: np.sin(x)
fp = lambda x: np.cos(x)
# Basic finite-difference formulas
def fp_forward(f, x, h):
return (f(x+h) - f(x)) / h
def fp_backward(f, x, h):
return (f(x) - f(x-h)) / h
def fp_central(f, x, h):
return (f(x+h) - f(x-h)) / (2*h)We pick a moderate step size and compare forward/backward/central differences against the analytic derivative. Central differences are usually much more accurate for smooth functions.
X = np.linspace(0, 2*np.pi, 201)
h = 0.1 # "reasonable" step for visual comparison
plt.plot(X, fp(X), label=r"Exact $f'(x)=\cos x$")
plt.plot(X, fp_forward (f, X, h), '-.', label=f'Forward (h={h:g})')
plt.plot(X, fp_backward(f, X, h), '--', label=f'Backward (h={h:g})')
plt.plot(X, fp_central (f, X, h), ':', label=f'Central (h={h:g})')
plt.xlabel('x')
plt.ylabel('derivative')
plt.legend()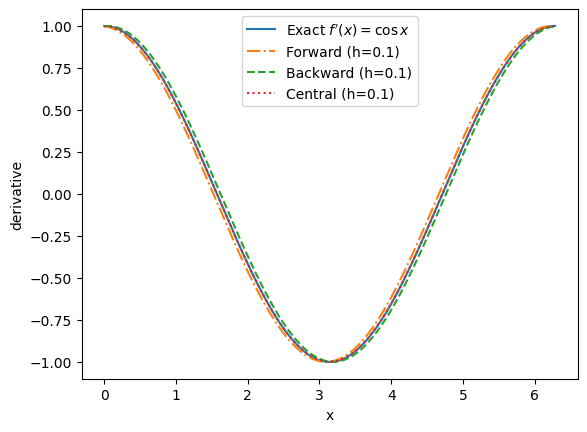
# HANDSON: Adjust `h` in the above cell and observe how the finite
# difference methods behave
Next, we perform a convergence study, i.e., how error changes with step size. We fix a point and sweep over many orders of magnitude.
def errors(f, fp_exact, x0):
# Step sizes spanning many orders of magnitude
H = np.logspace(0, -16, 17) # start at 1 down to 1e-16
fp = fp_exact(x0)
Ef = np.abs(fp_forward (f, x0, H) - fp)
Eb = np.abs(fp_backward(f, x0, H) - fp)
Ec = np.abs(fp_central (f, x0, H) - fp)
return H, Ef, Eb, Ec# Compare at a few points to see behavior across the domain
X0 = [0.3, np.pi/4, 1.7]
eps = np.finfo(float).eps
fig, axes = plt.subplots(1, len(X0), figsize=(12,4), sharey=True)
for ax, x0 in zip(axes, X0):
H, Ef, Eb, Ec = errors(f, fp, x0)
# Reference slopes: h and h^2 (scaled to match error at largest h for readability)
s1 = Ef[0]/H[0] # scale so line ~ same level at left
s2 = Ec[0]/(H[0]**2)
ax.loglog(H, s1*H, 'k--', lw=1, label=r'$\propto h$')
ax.loglog(H, s2*H**2, 'k:', lw=1, label=r'$\propto h^2$')
ax.loglog(H, Ef, 'o-', ms=3, label='Forward ($O(h)$)')
ax.loglog(H, Eb, 's--', ms=3, label='Backward ($O(h)$)')
ax.loglog(H, Ec, '^:' , ms=3, label='Central ($O(h^2)$)')
ax.set_title(f'$x_0 = {x0:.3f}$')
ax.set_ylim(1e-19, 1e+1)
ax.set_xlim(max(H)*2, min(H)/2)
ax.set_xlabel(r'Step size $h$')
# A helpful visual: round-off typically appears near sqrt(eps)
ax.axvline(eps**(1/2), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/2)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/2}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/3), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/3)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/3}$',
va='bottom', ha='right', color='k')
axes[0].set_ylabel('Error')
axes[2].legend(loc='lower right', ncol=1)
plt.tight_layout()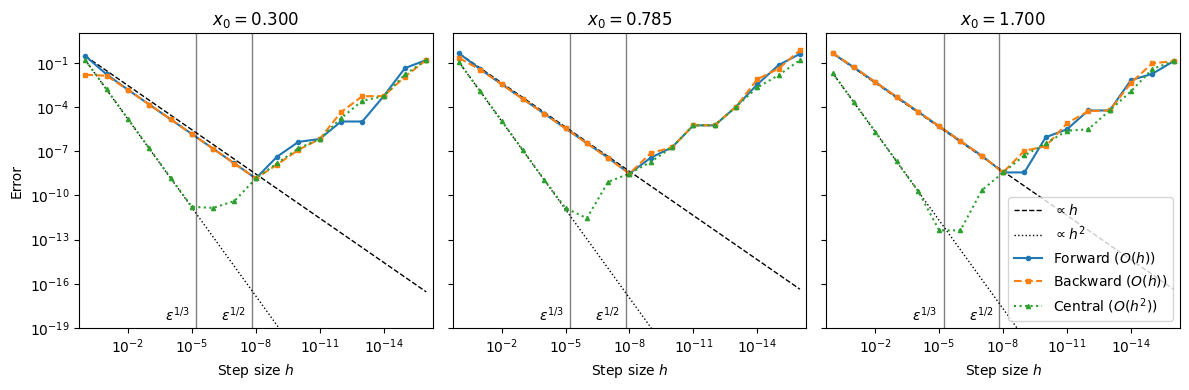
From the plot above, we observe that
For large , truncation error dominates: error scales like (forward/backward) or (central).
For small , round-off error dominates: subtractive cancellation makes the difference noisy, so error grows.
The “best” is somewhere in the middle (often near for th-order methods), where total error is minimized. However, this depends on the local scales of , etc.
# HANDSON: Change `x0` and observe how the convergence plots change.
# Specifically, what if `x0 = 0`?
# HANDSON: Find your optimal `h` at different points.
# In the convergence plot, read off the $h$ where each curve
# reaches its minimum.
# How does it change with the local behavior of $f(x)$?
# HANDSON: Find your optimal `h` for different functions.
# Specifically, replace $f(x)$ by $e^{-x^2}$ or $e^{3x}$.
# How do the error curves change?
# Which methods are more robust?
# HANDSON: Probe subtraction error.
# For a fixed tiny `h=10e-12`, evaluate `(f(x+h)-f(x))/h`
# as `x0` varies.
# Where does the error spike?
# Why?
“High-Order Finite Differences” as in High-Order Schemes¶
High-order finite differences improve the accuracy order of a derivative approximation by combining more sample points and cancelling lower-order error terms via Taylor expansions.
This should not be confused with computing higher-order derivatives (e.g., , ) that we will see later. Here, we still approximate a first derivative , but with higher-order accuracy.
To derive high-order finite difference approximations, the standard method is to use Taylor series expansion of the function around the point of interest. By considering multiple points symmetrically distributed around the target point, it is possible to eliminate lower-order error terms, thereby increasing the accuracy of the derivative approximation.
Specifically, consider approximating the first derivative with fourth-order accuracy. This requires that the truncation error be of order . Expand the function at points , , , and using the Taylor series around :
We will construct linear combinations of these expansions to eliminate the lower-order terms up to . For example, subtract the expansion at from that at and adjust coefficients to isolate :
It is now straightforward to eliminate the term:
Solving for :
This leads to the fourth-order central difference formula for the first derivative.
def fp_central4(f, x, h):
return (-f(x+2*h) + 8*f(x+h) - 8*f(x-h) + f(x-2*h))/(12*h)def errors(f, fp_exact, x0):
# Step sizes spanning many orders of magnitude
H = np.logspace(0, -16, 17) # start at 1 down to 1e-16
fp = fp_exact(x0)
Ef = np.abs(fp_forward (f, x0, H) - fp)
Eb = np.abs(fp_backward(f, x0, H) - fp)
Ec = np.abs(fp_central (f, x0, H) - fp)
Ec4= np.abs(fp_central4(f, x0, H) - fp)
return H, Ef, Eb, Ec, Ec4X0 = [0.3, np.pi/4, 1.7]
fig, axes = plt.subplots(1, len(X0), figsize=(12,4), sharey=True)
for ax, x0 in zip(axes, X0):
H, Ef, Eb, Ec, Ec4 = errors(f, fp, x0)
# Reference slopes: h and h^2 (scaled to match error at largest h for readability)
s1 = Ef [0]/H[0] # scale so line ~ same level at left
s2 = Ec [0]/(H[0]**2)
s4 = Ec4[0]/(H[0]**4)
ax.loglog(H, s1*H, 'k--', lw=1, label=r'$\propto h$')
ax.loglog(H, s2*H**2, 'k-.', lw=1, label=r'$\propto h^2$')
ax.loglog(H, s4*H**4, 'k:', lw=1, label=r'$\propto h^4$')
ax.loglog(H, Ef, 'o-', ms=3, label='Forward ($O(h)$)')
ax.loglog(H, Eb, 's--', ms=3, label='Backward ($O(h)$)')
ax.loglog(H, Ec, '^-.', ms=3, label='Central ($O(h^2)$)')
ax.loglog(H, Ec4,'^:' , ms=3, label='Central4 ($O(h^4)$)')
ax.set_title(f'$x_0 = {x0:.3f}$')
ax.set_ylim(1e-19, 1e+1)
ax.set_xlim(max(H)*2, min(H)/2)
ax.set_xlabel(r'Step size $h$')
# A helpful visual: round-off typically appears near sqrt(eps)
ax.axvline(eps**(1/2), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/2)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/2}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/3), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/3)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/3}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/5), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/5)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/5}$',
va='bottom', ha='right', color='k')
axes[0].set_ylabel('Error')
axes[2].legend(loc='lower right', ncol=1)
plt.tight_layout()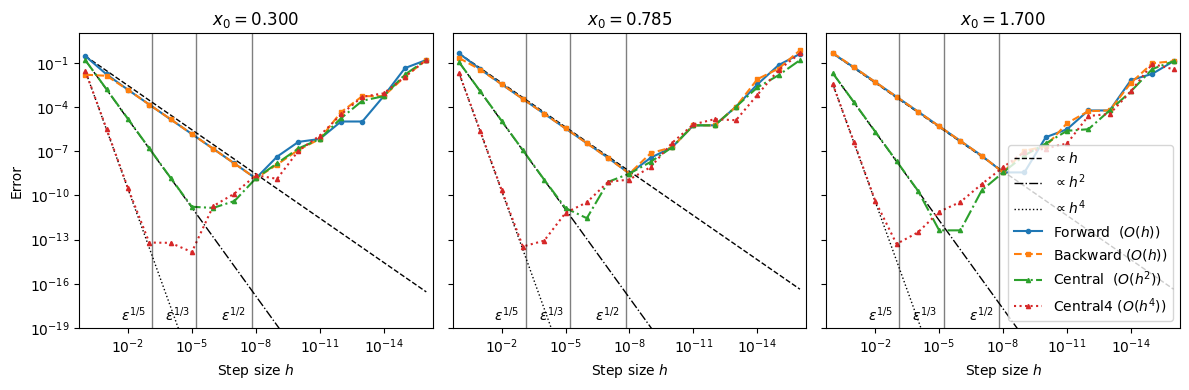
Does the 4th-order scheme converge as expected?
Yes, in the truncation regime (larger ) the error curve is parallel to .
No, for very small , the curve turns upward due to round-off and subtractive cancellation in differences like .
The “sweet spot” for the 4th-order stencil often occurs near , not as small as you might guess.
# HANDSON: Change `x0` and observe how the convergence plots change.
# Specifically, what if `x0 = 0` or `x0 = np.pi/2`?
# HANDSON: Find your optimal `h` at different points.
# In the convergence plot, read off the $h$ where each curve
# reaches its minimum.
# How does it change with the local behavior of $f(x)$?
# HANDSON: Find your optimal `h` for different functions.
# Specifically, replace $f(x)$ by $e^{-x^2}$ or $e^{3x}$.
# How do the error curves change?
# Which methods are more robust?
# HANDSON: Probe subtraction error.
# For a fixed tiny `h=10e-12`, evaluate the numerators
# as `x0` varies.
# Where does the error spike?
# Why?
Notes that
Tabulated coefficients for many high-order stencils (central and one-sided) are widely available and easy to implement.
Orders above 6th are rarely useful in floating-point arithmetic because round-off and problem noise usually dominate before the asymptotic order helps.
“High-Order Finite Differences” for Higher Derivatives¶
Finite differences extend naturally to higher derivatives. A standard example is the second derivative using the central 3-point stencil. Starting from Taylor expansions at ,
adding eliminates the odd derivatives and gives
so the 3-point central formula is
Below we implement this stencil, compare to the exact derivative for (so ), and run a convergence study. We also include a 5-point, stencil for higher accuracy.
# Test function and exact second derivative
f = lambda x: np.sin(x)
fpp = lambda x: -np.sin(x)
# 3-point central, O(h^2)
def fpp_central3(f, x, h):
return (f(x+h) - 2*f(x) + f(x-h)) / (h**2)
# 5-point central, O(h^4)
def fpp_central5(f, x, h):
return (-f(x+2*h) + 16*f(x+h) - 30*f(x) + 16*f(x-h) - f(x-2*h)) / (12*h**2)We compare the numerical second derivative with the exact one on a grid with a moderate step size . The 5-point stencil typically matches the exact curve noticeably better for smooth functions.
X = np.linspace(0, 2*np.pi, 201)
h = 1 # "reasonable" step for visual comparison
plt.plot(X, fpp(X), label=r"Exact $f''(x)=-\sin x$")
plt.plot(X, fpp_central3(f, X, h), '--', label=f'3-point central (h={h:g})')
plt.plot(X, fpp_central5(f, X, h), ':', label=f'5-point central (h={h:g})')
plt.xlabel('x')
plt.ylabel('Second derivative')
plt.legend()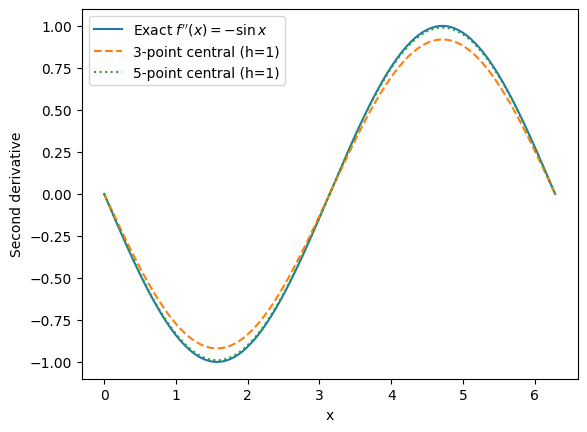
# HANDSON: Adjust `h` in the above cell and observe how the finite
# difference methods behave
As with first derivatives, we perform a convergence study. We fix a point and sweep over many orders of magnitude.
def error2s(f, fpp_exact, x0):
# Step sizes spanning many orders of magnitude
H = np.logspace(0, -16, 17) # start at 1 down to 1e-16
fpp = fpp_exact(x0)
E3 = np.abs(fpp_central3(f, x0, H) - fpp)
E5 = np.abs(fpp_central5(f, x0, H) - fpp)
return H, E3, E5# Compare at a few points to see behavior across the domain
X0 = [0.3, np.pi/4, 1.7]
eps = np.finfo(float).eps
fig, axes = plt.subplots(1, len(X0), figsize=(12,4), sharey=True)
for ax, x0 in zip(axes, X0):
H, E3, E5 = error2s(f, fpp, x0)
# Reference slopes: h and h^2 (scaled to match error at largest h for readability)
s2 = E3[0]/(H[0]**2) # scale so line ~ same level at left
s4 = E5[0]/(H[0]**4)
ax.loglog(H, s2*H**2, 'k--', lw=1, label=r'$\propto h^2$')
ax.loglog(H, s4*H**4, 'k:', lw=1, label=r'$\propto h^4$')
ax.loglog(H, E3, 'o-', ms=3, label='3-point central ($O(h^2)$)')
ax.loglog(H, E5, 's--', ms=3, label='5-point central ($O(h^4)$)')
ax.set_title(f'$x_0 = {x0:.3f}$')
ax.set_ylim(1e-15, 1e+5)
ax.set_xlim(max(H)*2, min(H)/2)
ax.set_xlabel(r'Step size $h$')
# A helpful visual: round-off typically appears near sqrt(eps)
ax.axvline(eps**(1/3), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/3)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/3}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/5), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/5)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/5}$',
va='bottom', ha='right', color='k')
axes[0].set_ylabel('Error')
axes[2].legend(loc='lower right', ncol=1)
plt.tight_layout()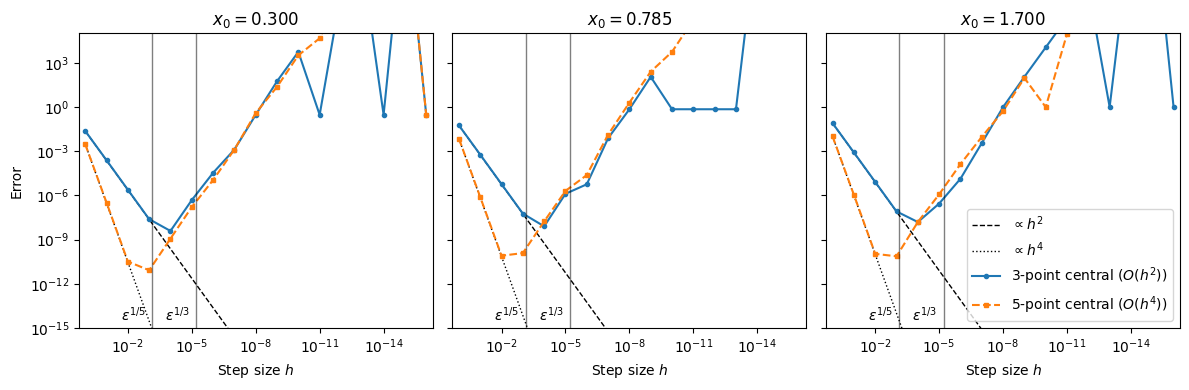
Just like for the first derivatives, why are the convergence plots not perfect? How do the truncation and round-off errors behave here?
# HANDSON: Change `x0` and observe how the convergence plots change.
# Specifically, what if `x0 = 0` or `x0 = np.pi/2`?
# HANDSON: Find your optimal `h` at different points.
# In the convergence plot, read off the $h$ where each curve
# reaches its minimum.
# How does it change with the local behavior of $f(x)$?
# HANDSON: Find your optimal `h` for different functions.
# Specifically, replace $f(x)$ by $e^{-x^2}$ or $e^{3x}$.
# How do the error curves change?
# Which methods are more robust?
# HANDSON: Probe subtraction error.
# For a fixed tiny `h=10e-12`, evaluate the numerators
# as `x0` varies.
# Where does the error spike?
# Why?
Spectral Derivatives (Fourier Method)¶
Spectral methods approximate derivatives by expanding a function in global basis functions (e.g., Fourier modes). For smooth, periodic functions, Fourier spectral methods often achieve spectral (near-exponential) convergence, far outpacing finite differences of any fixed order.
For a periodic function on ,
Differentiation in -space corresponds to multiplication in -space:
Thus, a numerical derivative is obtained by FFT, and then multiply by , and then inverse FFT.
# Spectral derivative
def fp_spectral(func, X):
F = func(X)
G = np.fft.fft(F)
K = 2 * np.pi * np.fft.fftfreq(len(X), d=X[1]-X[0])
# Multiply by ik to get derivative in frequency domain
Gp = 1j * K * G
# Inverse Fourier transform to get derivative in spatial domain
return np.fft.ifft(Gp).real# Number of modes
N = 32
L = 2 * np.pi
X = np.linspace(-L/2, L/2, N, endpoint=False)
plt.plot(X, fp(X), label=r"Exact $f'(x)=\cos x$")
plt.plot(X, fp_spectral(f, X), 'o-', label='Spectral Derivative')
plt.xlabel('x')
plt.ylabel('Derivative')
plt.legend()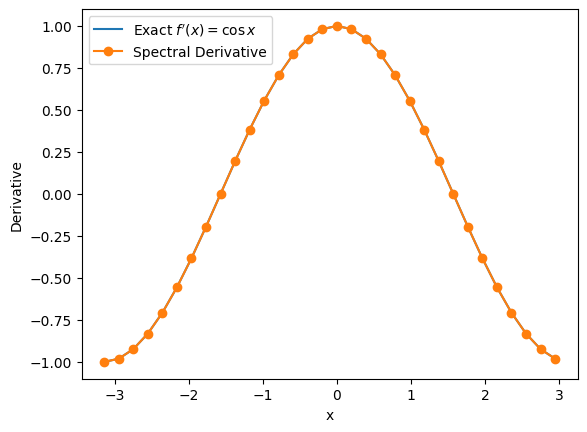
Spectral method works so well for is not surprising. It requires only a single Fourier mode to represent the function exactly. For other functions, note that the important assumptions:
The function is periodic on the chosen interval. If not, its periodic extension may be discontinuous, which will lead to Gibbs oscillations and slow convergence.
The sampling is uniform and we use the DFT/FFT grid.
# HANDSON: Create a convergence plot for spectral derivative.
# I.e., to study the effect of resolution.
# HANDSON: What is the effect of the domain size?
# HANDSON: What if the function is not perfectly periodic or has
# limited smoothness?
# Try out functions:
# 1. Gaussian $\exp(-x^2/2)$
# 2. Lorentzian $1/(1+x^2)$
# 3. Discontinuous functions
Complex-Step Differentiation¶
The complex-step method computes derivatives by evaluating the function at a complex perturbation and reading the derivative from the imaginary part.
Unlike finite differences, it avoids subtractive cancellation, so you can take very small without round-off blowup. For analytic functions (holomorphic in a neighborhood of ) that accept complex inputs, complex-step gives derivatives with near machine precision at modest cost.
Because there is no subtraction of nearly equal real values, there is no catastrophic cancellation. This typically allows using extremely small and achieving errors near floating-point limits.
# Complex-step derivative
def fp_complexstep(f, x, h=1e-100):
return np.imag(f(x + 1j*h)) / h
print(fp(x0))
print(fp_complexstep(f, x0))
print(abs(fp(x0) - fp_complexstep(f, x0)))-0.12884449429552464
-0.12884449429552464
0.0
def errors(f, fp_exact, x0):
# Step sizes spanning many orders of magnitude
H = np.logspace(0, -16, 17) # start at 1 down to 1e-16
fp = fp_exact(x0)
Ef = np.abs(fp_forward (f, x0, H) - fp)
Eb = np.abs(fp_backward (f, x0, H) - fp)
Ec = np.abs(fp_central (f, x0, H) - fp)
Ec4= np.abs(fp_central4 (f, x0, H) - fp)
Ecs= np.abs(fp_complexstep(f, x0, H) - fp)
return H, Ef, Eb, Ec, Ec4, EcsX0 = [0.3, np.pi/4, 1.7]
fig, axes = plt.subplots(1, len(X0), figsize=(12,4), sharey=True)
for ax, x0 in zip(axes, X0):
H, Ef, Eb, Ec, Ec4, Ecs = errors(f, fp, x0)
# Reference slopes: h and h^2 (scaled to match error at largest h for readability)
s1 = Ef [0]/H[0] # scale so line ~ same level at left
s2 = Ec [0]/(H[0]**2)
s4 = Ec4[0]/(H[0]**4)
ax.loglog(H, s1*H, 'k--', lw=1, label=r'$\propto h$')
ax.loglog(H, s2*H**2, 'k-.', lw=1, label=r'$\propto h^2$')
ax.loglog(H, s4*H**4, 'k:', lw=1, label=r'$\propto h^4$')
ax.loglog(H, Ef, 'o-', ms=3, label='Forward ($O(h)$)')
ax.loglog(H, Eb, 's--', ms=3, label='Backward ($O(h)$)')
ax.loglog(H, Ec, '^-.', ms=3, label='Central ($O(h^2)$)')
ax.loglog(H, Ecs,'^-.', ms=3, label='Complex Step ($O(h^2)$)')
ax.loglog(H, Ec4,'^:' , ms=3, label='Central4 ($O(h^4)$)')
ax.set_title(f'$x_0 = {x0:.3f}$')
ax.set_ylim(1e-19, 1e+1)
ax.set_xlim(max(H)*2, min(H)/2)
ax.set_xlabel(r'Step size $h$')
# A helpful visual: round-off typically appears near sqrt(eps)
ax.axvline(eps**(1/2), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/2)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/2}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/3), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/3)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/3}$',
va='bottom', ha='right', color='k')
ax.axvline(eps**(1/5), color='k', alpha=0.5, lw=1)
ax.text(eps**(1/5)*2, ax.get_ylim()[0]*2, r'$\epsilon^{1/5}$',
va='bottom', ha='right', color='k')
axes[0].set_ylabel('Error')
axes[2].legend(loc='lower right', ncol=1)
plt.tight_layout()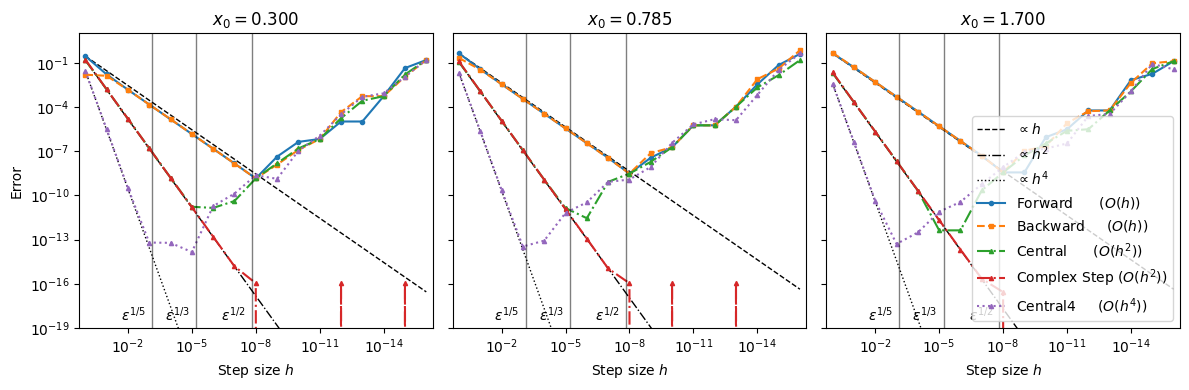
Based on the above code, complex-step is a simple, robust way to get high-accuracy first derivatives without round-off blowup. Although it converges only at second order, an extremely small step size can be used without introducing round-off errors. As a result, it is often much more accurate in practice than other, even higher-order, derivative methods. For many smooth problems, complex-step delivers near machine-precision accuracy with a single (complex) function evaluation per partial derivative.
# HANDSON: Replace `f` with `lambda x: np.abs(x)` or a function with
# `np.maximum(x)`.
# What happens and why?
# HANDSON: Compare methods.
# For a smooth function, compare complex-step, central,
# and 4th-order central at several points.
# Which reaches the lowest error for a given evaluation
# budget?
Note however the requirements and caveats:
must be analytic near and implemented so that it accepts complex inputs. Non-analytic operations (e.g.,
abs,max, branching on the sign of ) can break the method.Some libraries or user-defined code may not propagate complex types.
Automatic Differentiation¶
Automatic Differentiation (AD) is a computational technique that computes exact derivatives up to machine precision by systematically applying the chain rule at the level of elementary operations.
Unlike symbolic differentiation, which manipulates algebraic expressions, and numerical differentiation, which approximates derivatives with finite differences, AD directly tracks derivatives during computation. This avoids the expression growth problem of symbolic methods and the round-off/truncation errors of finite differences.
AD has become indispensable in modern scientific computing, optimization, and machine learning, where accurate gradient information is critical.
AD operates in two main modes:
Forward mode: efficient when the number of inputs is small and the number of outputs is large.
Reverse mode: efficient when the number of outputs is small and the number of inputs is large (this is the mode used in deep learning).
Dual Numbers and Forward Mode AD¶
Forward mode AD can be understood using dual numbers, a simple but powerful extension of real numbers. A dual number is written as:
where:
is the real part (the function value),
is the dual part, which is the derivative, and
is an infinitesimal number with the special property .
This algebra means that higher-order terms vanish, leaving only the first derivative information. For example:
Notice that the derivative naturally follows from the multiplication rule, and similar results hold for all other operations (addition, division, sin, exp, etc.).
This is precisely what forward mode AD does: it propagates both values and derivatives through the computation using the chain rule.
Example: Differentiating ¶
Consider the function . Using dual numbers:
Since , the dual part of is , which is the derivative .
Implementing Autodiff with Dual Numbers¶
To implement forward mode AD in Python, we can define a Dual class
that overrides arithmetic operations to handle both the value and
derivative parts.
Additionally, we introduce helper functions V(x) and D(x) to
extract the value and derivative from Dual Numbers or regular
numerical inputs.
def V(x):
"""Select the value from a dual number.
Work for both python built-in numbers (often used in function) and dual numbers.
"""
if isinstance(x, Dual):
return x[0]
else:
return x
def D(x):
"""Select the derivative from a dual number.
Work for both python built-in numbers (often used in function) and dual numbers.
"""
if isinstance(x, Dual):
return x[1]
else:
return 0class Dual(tuple):
"""Dual number for implementing autodiff in pure python"""
def __new__(self, v, d=1): # tuple is immutable so we cannot use __init__()
return tuple.__new__(Dual, (v, d))
def __add__(self, r):
return Dual(
V(self) + V(r),
D(self) + D(r),
)
def __radd__(self, l):
return self + l # addition commutes
def __sub__(self, r):
return Dual(
V(self) - V(r),
D(self) - D(r),
)
def __rsub__(self, l):
return Dual(
V(l) - V(self),
D(l) - D(self),
)
def __mul__(self, r):
return Dual(
V(self) * V(r),
D(self) * V(r) + V(self) * D(r),
)
def __rmul__(self, l):
return self * l # multiplication commutes
def __truediv__(self, r):
return Dual(
V(self) / V(r),
..., # leave as HANDSON
)
def __rtruediv__(self, l):
return Dual(
V(l) / V(self),
..., # leave as HANDSON
)
def __pow__(self, r): # assume r is constant
if r == 0:
return ... # leave as HANDSON
elif r == 1:
return ... # leave as HANDSON
else:
return Dual(
V(self)**r,
..., # leave as HANDSON
)That’s it! We’ve implemented (a limited version of) autodiff in pure python!
To validate our Dual Number implementation, we define a simple function and compute its derivative using AD. Consider the function . We evaluate this function using Dual Numbers and plot both the function and its derivative.
def f(x):
return x + x*x
X = np.linspace(-1,1,num=11)
F, Fp = f(Dual(X))
Xd = np.linspace(min(X), max(X), num=1001)
Fd = [f(x) for x in Xd]
plt.plot(Xd, Fd, lw=5, alpha=0.25)
for (x, fp) in zip(X, Fp):
y = f(x)
plt.plot(
[x-0.05, x+0.05],
[y-0.05*fp, y+0.05*fp],
)
plt.xlabel('x')
plt.ylabel('f(x)')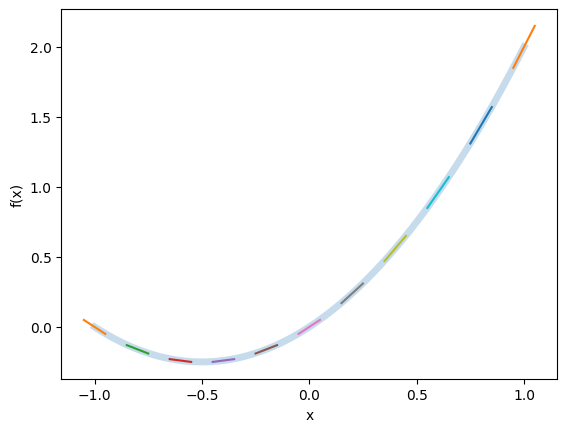
The initial implementation of the Dual class handles basic arithmetic operations. However, to support more complex functions such as trigonometric functions, we need to define additional operations that correctly propagate derivative information. This can be achieved by implementing helper functions that operate on Dual Numbers.
def sin(x):
return Dual(
np.sin(V(x)),
np.cos(V(x)) * D(x) # chain rule: d/dx sin(x) = cos(x) * x'
)def f(x):
return sin(x + x*x)
X = np.linspace(-1, 1, 1001)
F, Fp = f(Dual(X))
plt.plot(X, F, lw=5, alpha=0.25)
for (x, f, fp) in list(zip(X, F, Fp))[::100]:
plt.plot(
[x-0.05, x+0.05],
[f-0.05*fp, f+0.05*fp],
)
plt.xlabel('x')
plt.ylabel('f(x)')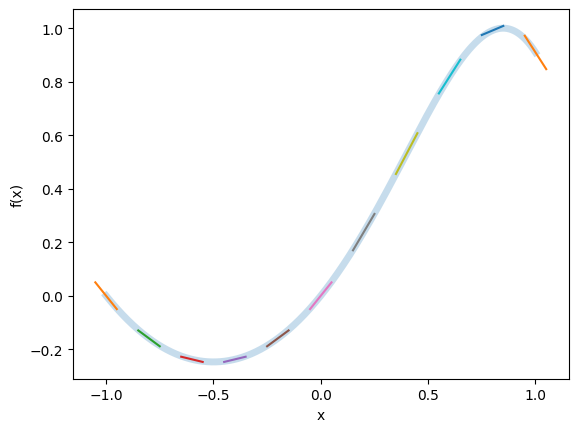
# HANDSON: test the accuracy of Dual number autodiff.
# Does it reach machine accuracy?
# HANDSON: implement __truediv__() and __rtruediv__() in `Dual` to
# support division.
# Test it with functions like the Lorentzian $1/(1+x^2)$.
# HANDSON: implement __pow__() in `Dual` and test it.
Connection to the Complex Step Method¶
While the function implementation looks different, the dual number formulation is computationally very similar to the complex-step method we discussed earlier. Both approaches introduce an extra component, either a dual part () or an imaginary part (), to carry derivative information without large numerical errors.
In the Complex Step Method, we evaluate the function at a perturbed point , where is a small real step size:
The imaginary part directly gives the derivative:
The real part includes an extra term , which becomes negligible when is sufficiently small. In fact, for , where is the machine precision, this term vanishes due to round-off limitations. Thus, we expect the “real part” of a complex step operation would match the real part of a Dual number. In other words, when the step size is chosen carefully, the complex step method essentially behaves like the dual number formulation.
Reverse Mode AD¶
Forward mode AD, as we saw with dual numbers, is most efficient when a function has only a few inputs. However, when there are many inputs but only a single output, reverse mode AD becomes much more powerful. This is exactly the case in machine learning, where models may contain millions of parameters but the objective is often to minimize a single scalar loss function.
The key idea of reverse mode AD is to build a computational graph that records the sequence of operations performed during the forward evaluation of the function. Once the function value has been computed, the graph is traversed backward, propagating sensitivities (gradients) from the output back to the inputs. At each step, the chain rule is applied systematically, allowing the derivative with respect to every input to be obtained in a single backward pass. This process is commonly known as backpropagation.
In practice, reverse mode AD requires storing or recomputing intermediate values from the forward pass, which can be memory intensive. Modern machine learning frameworks such as TensorFlow, PyTorch, and JAX implement reverse mode efficiently by combining graph-based differentiation with optimizations like checkpointing, where only a subset of intermediate results are stored and the rest are recomputed as needed.
Autodiff (with Vectorization and JIT) in Python using JAX¶
JAX is a high-performance numerical computing library developed by Google. It extends the familiar NumPy API with powerful tools for automatic differentiation (AD). This makes it especially useful in machine learning, optimization, and scientific computing. One of JAX’s strengths is that it combines ease of use with Just-In-Time (JIT) compilation and allows Python code to be executed efficiently on CPUs and GPUs.
Key features of JAX includes:
Automatic Differentiation: JAX supports both forward and reverse mode AD, enabling efficient computation of derivatives, gradients, Jacobians, and Hessians.
JIT Compilation: Through XLA (Accelerated Linear Algebra), JAX can compile Python functions into optimized machine code, often yielding dramatic speedups.
Vectorization: With the function
vmap, JAX makes it easy to apply functions across entire arrays without writing explicit loops.Composability and Interoperability: JAX code looks and feels like NumPy. Minimal changes are needed to benefit from AD, vectorization, or JIT, and these transformations can be composed seamlessly.
To install JAX on a CPU-only system, use:
pip install --upgrade "jax[cpu]"For GPU acceleration, the installation requires CUDA-enabled builds. See the JAX documentation for details.
Let’s demonstrate how to use JAX to compute and visualize derivatives.
!pip install jaxRequirement already satisfied: jax in /Users/ckc/.venv/teach/lib/python3.13/site-packages (0.4.38)
Requirement already satisfied: jaxlib<=0.4.38,>=0.4.38 in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from jax) (0.4.38)
Requirement already satisfied: ml_dtypes>=0.4.0 in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from jax) (0.5.3)
Requirement already satisfied: numpy>=1.24 in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from jax) (2.3.3)
Requirement already satisfied: opt_einsum in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from jax) (3.4.0)
Requirement already satisfied: scipy>=1.10 in /Users/ckc/.venv/teach/lib/python3.13/site-packages (from jax) (1.16.2)
from jax import numpy as jnp, grad, vmap
# Define the function
def f(x):
return jnp.sin(x + x*x)
# Grid of input points
X = jnp.linspace(-1, 1, num=1001)
# Evaluate function and derivative
F = f(X)
Fp = vmap(grad(f))(X)
# Plot function and tangent lines
plt.plot(X, F, lw=5, alpha=0.25)
for (x, f, fp) in list(zip(X, F, Fp))[::100]:
plt.plot(
[x-0.05, x+0.05],
[f-0.05*fp, f+0.05*fp],
)
plt.xlabel('x')
plt.ylabel('f(x)')This example shows how seamlessly JAX can compute derivatives and
apply them across entire arrays.
The combination of autodiff, vectorization (vmap), and JIT
compilation (jit) makes JAX an exceptionally powerful tool for
large-scale scientific computing.
# HANDSON: test out different JAX features
# HANDSON: benchmark JAX with NumPy, especially on machines with GPUs.
# Does `jit` make your code faster?
Summary¶
Differentiation is one of the most fundamental tools in mathematics, science, and engineering. It enables the analysis of functions, the modeling of physical systems, and the optimization of complex problems. Today, we explored several approaches to computing derivatives, each with its own advantages and limitations.
Symbolic Differentiation produces exact analytical expressions and is ideal for theoretical work. However, it often suffers from expression growth and can become computationally impractical for large or complex problems.
Numerical Differentiation (finite differences and spectral difference) provides a simple and flexible way to approximate derivatives using sampled function values. Its main challenge is balancing truncation error (improved with smaller step sizes) against round-off error (which grows with very small steps). Choosing an optimal step size is essential for stable results.
Complex Step Differentiation avoids the round-off error problem by perturbing the input in the imaginary direction. It achieves machine-precision accuracy for smooth functions and is, in fact, numerically equivalent to the dual number formulation used in forward mode AD when the step size is sufficiently small.
Automatic Differentiation (AD) bridges symbolic and numerical approaches by applying the chain rule systematically through a computational graph. It delivers exact derivatives up to machine precision without symbolic manipulation.
Forward mode AD (e.g., via dual numbers) is efficient when there are few inputs.
Reverse mode AD (backpropagation) is ideal for problems with many inputs but only a single output, such as neural network training.
Although powerful, AD can be memory-intensive and requires careful handling of non-differentiable functions and dynamic control flow.
Current research continues to push AD toward greater scalability for large models, efficient computation of higher-order derivatives (Jacobians, Hessians), and robust handling of non-differentiable functions and dynamic graphs. Future progress may come from hybrid approaches that combine the strengths of symbolic, numerical, and automatic differentiation.
For more information, please look into: